

概览
在本教程中,我们将使用LangGraph构建一个检索代理。 LangChain提供了使用LangGraph原语实现的内置代理实现。如果需要更深层次的定制,可以直接在LangGraph中实现代理。本指南演示了检索代理的示例实现。当您希望LLM决定是从向量存储中检索上下文还是直接回复用户时,检索代理非常有用。 在本教程结束时,我们将完成以下任务:- 获取和预处理将用于检索的文档。
- 索引这些文档以进行语义搜索,并为代理创建一个检索器工具。
- 构建一个能够决定何时使用检索器工具的智能RAG系统。
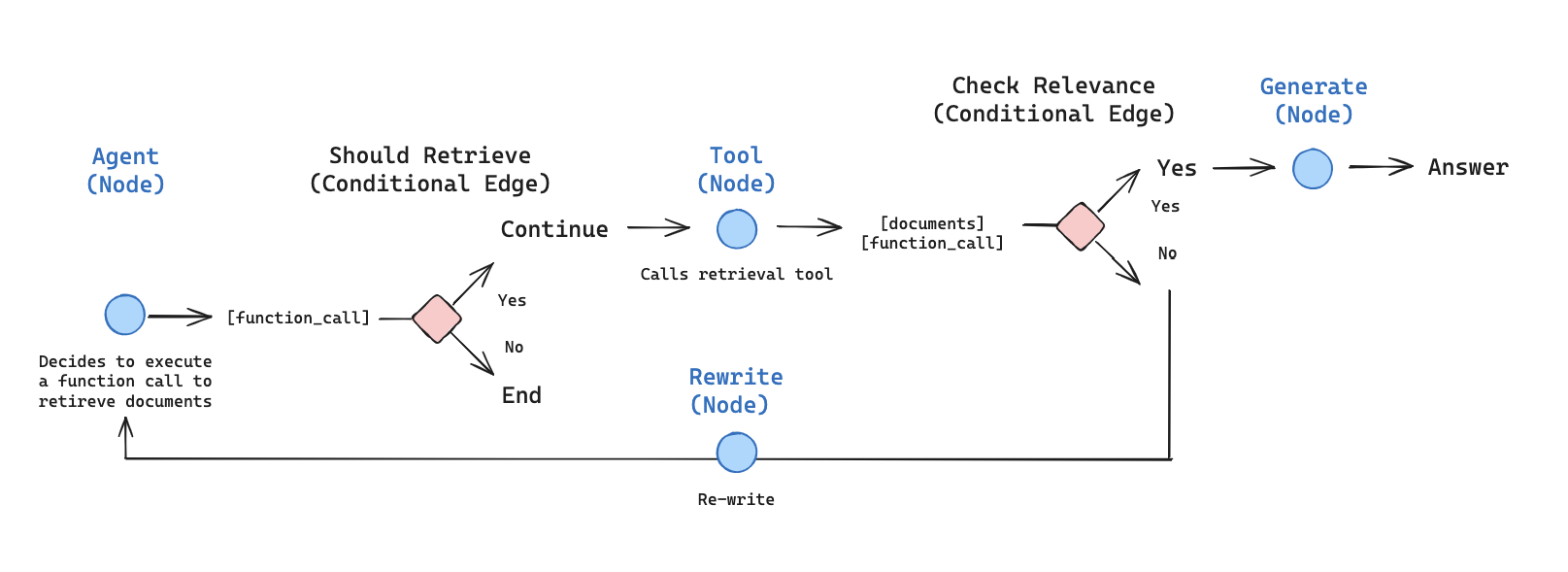
概念
我们将涵盖以下概念设置
让我们下载所需的包并设置我们的API密钥复制
向 AI 提问
npm install @langchain/langgraph @langchain/openai @langchain/community @langchain/textsplitters
注册LangSmith以快速发现问题并提高LangGraph项目的性能。LangSmith允许您使用跟踪数据来调试、测试和监控您使用LangGraph构建的LLM应用程序。
1. 预处理文档
- 获取要在我们的RAG系统中使用的文档。我们将使用来自Lilian Weng的优秀博客的最新三页。我们首先使用
CheerioWebBaseLoader获取页面内容
复制
向 AI 提问
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
const urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
];
const docs = await Promise.all(
urls.map((url) => new CheerioWebBaseLoader(url).load()),
);
- 将获取的文档分割成较小的块,以便索引到我们的向量存储中
复制
向 AI 提问
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
const docsList = docs.flat();
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
});
const docSplits = await textSplitter.splitDocuments(docsList);
2. 创建检索器工具
现在我们有了分割好的文档,我们可以将它们索引到向量存储中,用于语义搜索。- 使用内存中的向量存储和OpenAI嵌入
复制
向 AI 提问
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
import { OpenAIEmbeddings } from "@langchain/openai";
const vectorStore = await MemoryVectorStore.fromDocuments(
docSplits,
new OpenAIEmbeddings(),
);
const retriever = vectorStore.asRetriever();
- 使用LangChain预构建的
createRetrieverTool创建检索器工具
复制
向 AI 提问
import { createRetrieverTool } from "@langchain/classic/tools/retriever";
const tool = createRetrieverTool(
retriever,
{
name: "retrieve_blog_posts",
description:
"Search and return information about Lilian Weng blog posts on LLM agents, prompt engineering, and adversarial attacks on LLMs.",
},
);
const tools = [tool];
3. 生成查询
现在我们开始为我们的智能RAG图构建组件(节点和边)。- 构建一个
generateQueryOrRespond节点。它将调用LLM根据当前图状态(消息列表)生成响应。给定输入消息,它将决定是使用检索器工具进行检索,还是直接回复用户。请注意,我们通过.bindTools授予聊天模型访问我们之前创建的tools的权限
复制
向 AI 提问
import { ChatOpenAI } from "@langchain/openai";
async function generateQueryOrRespond(state) {
const { messages } = state;
const model = new ChatOpenAI({
model: "gpt-4o",
temperature: 0,
}).bindTools(tools);
const response = await model.invoke(messages);
return {
messages: [response],
};
}
- 在随机输入上尝试它
复制
向 AI 提问
import { HumanMessage } from "@langchain/core/messages";
const input = { messages: [new HumanMessage("hello!")] };
const result = await generateQueryOrRespond(input);
console.log(result.messages[0]);
复制
向 AI 提问
AIMessage {
content: "Hello! How can I help you today?",
tool_calls: []
}
- 提出需要语义搜索的问题
复制
向 AI 提问
const input = {
messages: [
new HumanMessage("What does Lilian Weng say about types of reward hacking?")
]
};
const result = await generateQueryOrRespond(input);
console.log(result.messages[0]);
复制
向 AI 提问
AIMessage {
content: "",
tool_calls: [
{
name: "retrieve_blog_posts",
args: { query: "types of reward hacking" },
id: "call_...",
type: "tool_call"
}
]
}
4. 评估文档
- 添加一个节点 —
gradeDocuments— 用于确定检索到的文档是否与问题相关。我们将使用带有Zod的结构化输出模型进行文档评分。我们还将添加一个条件边 —checkRelevance— 它检查评分结果并返回要跳转的节点名称(generate或rewrite)
复制
向 AI 提问
import * as z from "zod";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { ChatOpenAI } from "@langchain/openai";
import { AIMessage } from "@langchain/core/messages";
const prompt = ChatPromptTemplate.fromTemplate(
`You are a grader assessing relevance of retrieved docs to a user question.
Here are the retrieved docs:
\n ------- \n
{context}
\n ------- \n
Here is the user question: {question}
If the content of the docs are relevant to the users question, score them as relevant.
Give a binary score 'yes' or 'no' score to indicate whether the docs are relevant to the question.
Yes: The docs are relevant to the question.
No: The docs are not relevant to the question.`,
);
const gradeDocumentsSchema = z.object({
binaryScore: z.string().describe("Relevance score 'yes' or 'no'"),
})
async function gradeDocuments(state) {
const { messages } = state;
const model = new ChatOpenAI({
model: "gpt-4o",
temperature: 0,
}).withStructuredOutput(gradeDocumentsSchema);
const score = await prompt.pipe(model).invoke({
question: messages.at(0)?.content,
context: messages.at(-1)?.content,
});
if (score.binaryScore === "yes") {
return "generate";
}
return "rewrite";
}
- 在工具响应中包含不相关文档的情况下运行此操作
复制
向 AI 提问
import { ToolMessage } from "@langchain/core/messages";
const input = {
messages: [
new HumanMessage("What does Lilian Weng say about types of reward hacking?"),
new AIMessage({
tool_calls: [
{
type: "tool_call",
name: "retrieve_blog_posts",
args: { query: "types of reward hacking" },
id: "1",
}
]
}),
new ToolMessage({
content: "meow",
tool_call_id: "1",
})
]
}
const result = await gradeDocuments(input);
- 确认相关文档已分类
复制
向 AI 提问
const input = {
messages: [
new HumanMessage("What does Lilian Weng say about types of reward hacking?"),
new AIMessage({
tool_calls: [
{
type: "tool_call",
name: "retrieve_blog_posts",
args: { query: "types of reward hacking" },
id: "1",
}
]
}),
new ToolMessage({
content: "reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering",
tool_call_id: "1",
})
]
}
const result = await gradeDocuments(input);
5. 重写问题
- 构建
rewrite节点。检索器工具可能会返回不相关的文档,这表明需要改进原始用户问题。为此,我们将调用rewrite节点
复制
向 AI 提问
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { ChatOpenAI } from "@langchain/openai";
const rewritePrompt = ChatPromptTemplate.fromTemplate(
`Look at the input and try to reason about the underlying semantic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question:`,
);
async function rewrite(state) {
const { messages } = state;
const question = messages.at(0)?.content;
const model = new ChatOpenAI({
model: "gpt-4o",
temperature: 0,
});
const response = await rewritePrompt.pipe(model).invoke({ question });
return {
messages: [response],
};
}
- 试用
复制
向 AI 提问
import { HumanMessage, AIMessage, ToolMessage } from "@langchain/core/messages";
const input = {
messages: [
new HumanMessage("What does Lilian Weng say about types of reward hacking?"),
new AIMessage({
content: "",
tool_calls: [
{
id: "1",
name: "retrieve_blog_posts",
args: { query: "types of reward hacking" },
type: "tool_call"
}
]
}),
new ToolMessage({ content: "meow", tool_call_id: "1" })
]
};
const response = await rewrite(input);
console.log(response.messages[0].content);
复制
向 AI 提问
What are the different types of reward hacking described by Lilian Weng, and how does she explain them?
6. 生成答案
- 构建
generate节点:如果通过了评估器检查,我们可以根据原始问题和检索到的上下文生成最终答案
复制
向 AI 提问
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { ChatOpenAI } from "@langchain/openai";
async function generate(state) {
const { messages } = state;
const question = messages.at(0)?.content;
const context = messages.at(-1)?.content;
const prompt = ChatPromptTemplate.fromTemplate(
`You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}`
);
const llm = new ChatOpenAI({
model: "gpt-4o",
temperature: 0,
});
const ragChain = prompt.pipe(llm);
const response = await ragChain.invoke({
context,
question,
});
return {
messages: [response],
};
}
- 试一试
复制
向 AI 提问
import { HumanMessage, AIMessage, ToolMessage } from "@langchain/core/messages";
const input = {
messages: [
new HumanMessage("What does Lilian Weng say about types of reward hacking?"),
new AIMessage({
content: "",
tool_calls: [
{
id: "1",
name: "retrieve_blog_posts",
args: { query: "types of reward hacking" },
type: "tool_call"
}
]
}),
new ToolMessage({
content: "reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering",
tool_call_id: "1"
})
]
};
const response = await generate(input);
console.log(response.messages[0].content);
复制
向 AI 提问
Lilian Weng categorizes reward hacking into two types: environment or goal misspecification, and reward tampering. She considers reward hacking as a broad concept that includes both of these categories. Reward hacking occurs when an agent exploits flaws or ambiguities in the reward function to achieve high rewards without performing the intended behaviors.
7. 组装图
现在我们将把所有节点和边组装成一个完整的图- 从
generateQueryOrRespond开始,并确定是否需要调用检索器工具 - 使用条件边路由到下一步
- 如果
generateQueryOrRespond返回tool_calls,则调用检索器工具检索上下文 - 否则,直接回复用户
- 如果
- 评估检索到的文档内容与问题的相关性(
gradeDocuments)并路由到下一步- 如果不相关,使用
rewrite重写问题,然后再次调用generateQueryOrRespond - 如果相关,则继续到
generate并使用带有检索到的文档上下文的@[ToolMessage]生成最终响应
- 如果不相关,使用
复制
向 AI 提问
import { StateGraph, START, END } from "@langchain/langgraph";
import { ToolNode } from "@langchain/langgraph/prebuilt";
import { AIMessage } from "langchain";
// Create a ToolNode for the retriever
const toolNode = new ToolNode(tools);
// Helper function to determine if we should retrieve
function shouldRetrieve(state) {
const { messages } = state;
const lastMessage = messages.at(-1);
if (AIMessage.isInstance(lastMessage) && lastMessage.tool_calls.length) {
return "retrieve";
}
return END;
}
// Define the graph
const builder = new StateGraph(GraphState)
.addNode("generateQueryOrRespond", generateQueryOrRespond)
.addNode("retrieve", toolNode)
.addNode("gradeDocuments", gradeDocuments)
.addNode("rewrite", rewrite)
.addNode("generate", generate)
// Add edges
.addEdge(START, "generateQueryOrRespond")
// Decide whether to retrieve
.addConditionalEdges("generateQueryOrRespond", shouldRetrieve)
.addEdge("retrieve", "gradeDocuments")
// Edges taken after grading documents
.addConditionalEdges(
"gradeDocuments",
// Route based on grading decision
(state) => {
// The gradeDocuments function returns either "generate" or "rewrite"
const lastMessage = state.messages.at(-1);
return lastMessage.content === "generate" ? "generate" : "rewrite";
}
)
.addEdge("generate", END)
.addEdge("rewrite", "generateQueryOrRespond");
// Compile
const graph = builder.compile();
8. 运行智能RAG
现在,让我们通过向其提出问题来测试完整的图复制
向 AI 提问
import { HumanMessage } from "@langchain/core/messages";
const inputs = {
messages: [
new HumanMessage("What does Lilian Weng say about types of reward hacking?")
]
};
for await (const output of await graph.stream(inputs)) {
for (const [key, value] of Object.entries(output)) {
const lastMsg = output[key].messages[output[key].messages.length - 1];
console.log(`Output from node: '${key}'`);
console.log({
type: lastMsg._getType(),
content: lastMsg.content,
tool_calls: lastMsg.tool_calls,
});
console.log("---\n");
}
}
复制
向 AI 提问
Output from node: 'generateQueryOrRespond'
{
type: 'ai',
content: '',
tool_calls: [
{
name: 'retrieve_blog_posts',
args: { query: 'types of reward hacking' },
id: 'call_...',
type: 'tool_call'
}
]
}
---
Output from node: 'retrieve'
{
type: 'tool',
content: '(Note: Some work defines reward tampering as a distinct category...\n' +
'At a high level, reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering.\n' +
'...',
tool_calls: undefined
}
---
Output from node: 'generate'
{
type: 'ai',
content: 'Lilian Weng categorizes reward hacking into two types: environment or goal misspecification, and reward tampering. She considers reward hacking as a broad concept that includes both of these categories. Reward hacking occurs when an agent exploits flaws or ambiguities in the reward function to achieve high rewards without performing the intended behaviors.',
tool_calls: []
}
---
以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。