

目标
在这个例子中,我们将构建一个机器人,根据 GitHub 问题的标题对其进行分类。它将接收一个标题并将其分类到许多不同的类别之一。然后,我们将开始收集用户反馈,并使用它来调整分类器的性能。入门
首先,我们将设置它,以便将所有跟踪发送到特定项目。我们可以通过设置环境变量来完成此操作设置自动化
我们现在可以设置自动化,将带有某种形式反馈的示例移动到数据集中。我们将设置两个自动化,一个用于积极反馈,另一个用于消极反馈。 第一个将接收所有带有积极反馈的运行,并自动将其添加到数据集中。这背后的逻辑是,任何带有积极反馈的运行我们都可以在未来的迭代中用作良好示例。让我们创建一个名为classifier-github-issues 的数据集来添加此数据。 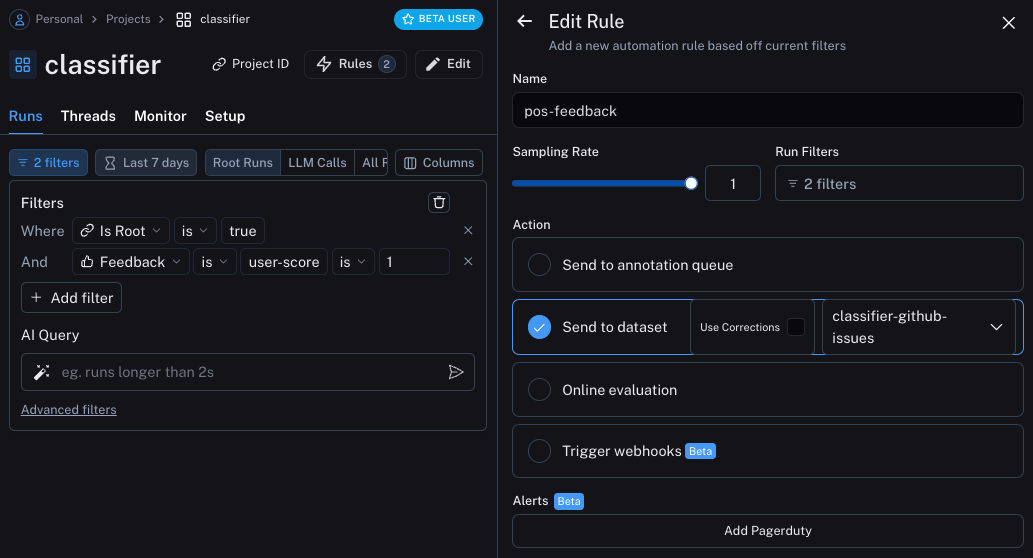
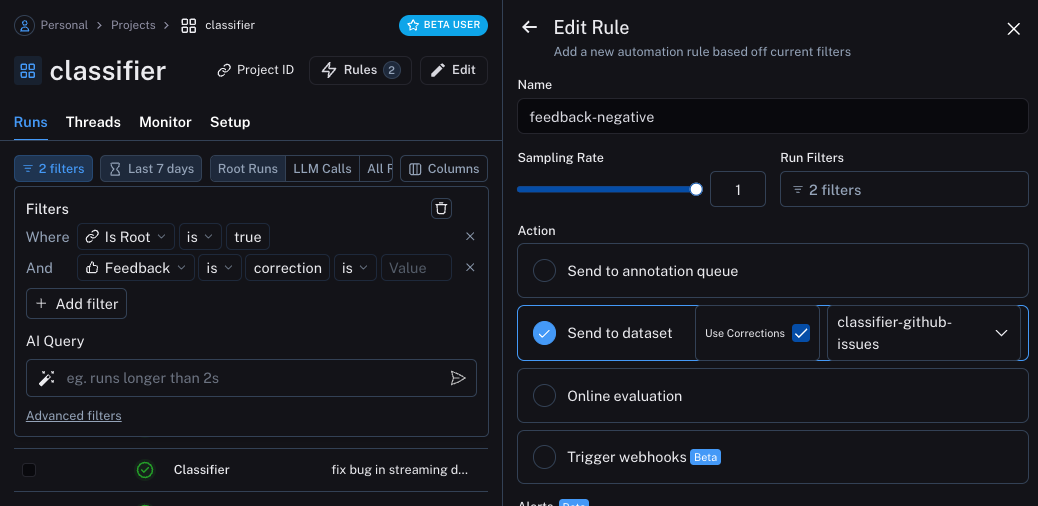
更新应用程序
我们现在可以更新我们的代码,以下载我们正在发送运行的数据集。下载后,我们可以创建一个包含示例的字符串。然后我们可以将此字符串作为提示的一部分!documentation
示例的语义搜索
我们可以做的另一件事是只使用语义最相似的示例。当您开始积累大量示例时,这很有用。 为此,我们首先可以定义一个示例来查找k 个最相似的示例:以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。