

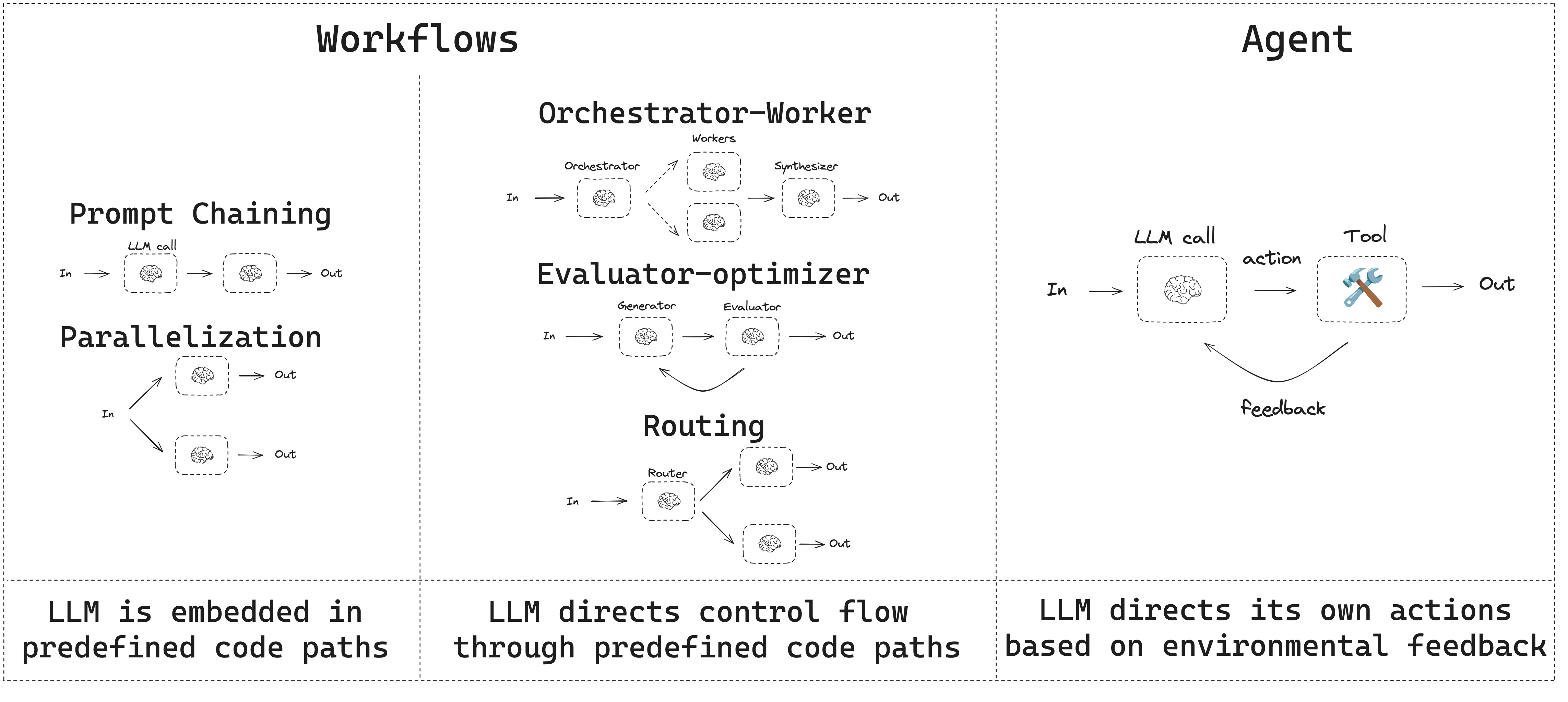
- 工作流具有预定的代码路径,并设计为按特定顺序操作。
- 代理是动态的,并定义自己的流程和工具使用。
设置
要构建工作流或代理,您可以使用任何支持结构化输出和工具调用的聊天模型。以下示例使用 Anthropic- 安装依赖项
复制
向 AI 提问
npm install @langchain/langgraph @langchain/core
- 初始化大型语言模型(LLM)
复制
向 AI 提问
import { ChatAnthropic } from "@langchain/anthropic";
const llm = new ChatAnthropic({
model: "claude-sonnet-4-5-20250929",
apiKey: "<your_anthropic_key>"
});
大型语言模型和增强
工作流和代理系统基于大型语言模型(LLM)及其添加的各种增强功能。工具调用、结构化输出和短期记忆是根据您的需求定制大型语言模型的一些选项。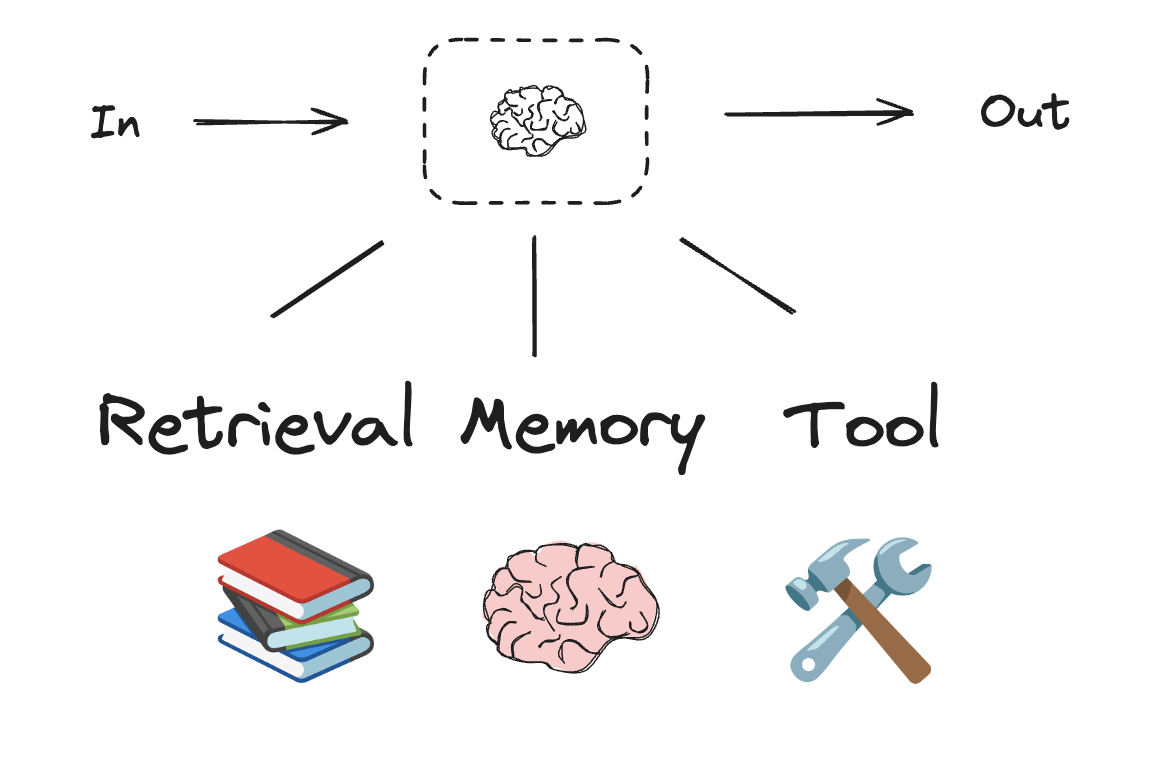
复制
向 AI 提问
import * as z from "zod";
import { tool } from "langchain";
// Schema for structured output
const SearchQuery = z.object({
search_query: z.string().describe("Query that is optimized web search."),
justification: z
.string()
.describe("Why this query is relevant to the user's request."),
});
// Augment the LLM with schema for structured output
const structuredLlm = llm.withStructuredOutput(SearchQuery);
// Invoke the augmented LLM
const output = await structuredLlm.invoke(
"How does Calcium CT score relate to high cholesterol?"
);
// Define a tool
const multiply = tool(
({ a, b }) => {
return a * b;
},
{
name: "multiply",
description: "Multiply two numbers",
schema: z.object({
a: z.number(),
b: z.number(),
}),
}
);
// Augment the LLM with tools
const llmWithTools = llm.bindTools([multiply]);
// Invoke the LLM with input that triggers the tool call
const msg = await llmWithTools.invoke("What is 2 times 3?");
// Get the tool call
console.log(msg.tool_calls);
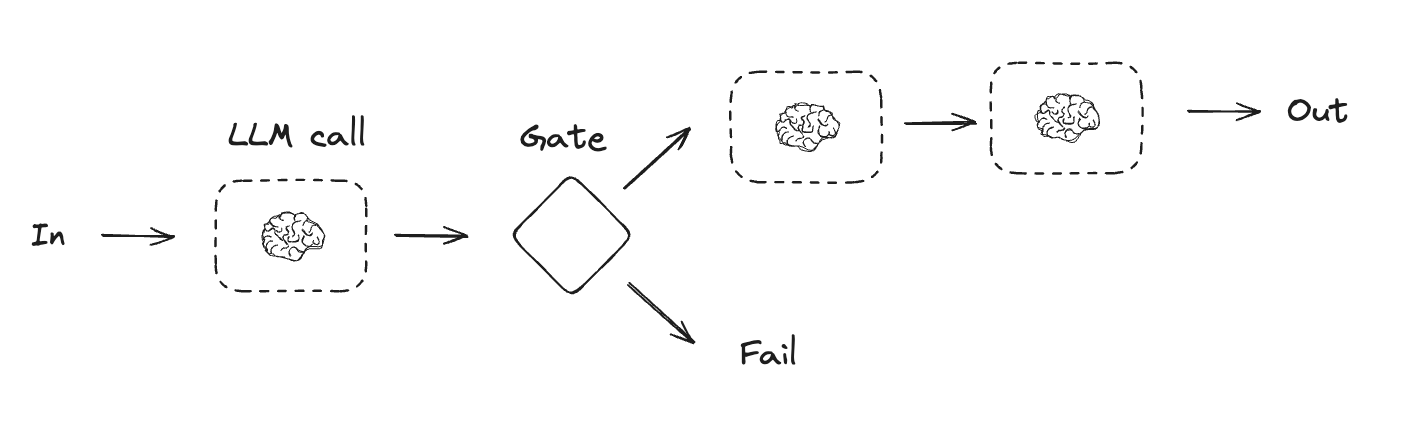
提示链
提示链是指每次大型语言模型调用都处理前一次调用的输出。它通常用于执行可以分解为更小、可验证步骤的明确任务。一些示例包括:- 将文档翻译成不同的语言
- 验证生成内容的一致性
复制
向 AI 提问
import { StateGraph, Annotation } from "@langchain/langgraph";
// Graph state
const StateAnnotation = Annotation.Root({
topic: Annotation<string>,
joke: Annotation<string>,
improvedJoke: Annotation<string>,
finalJoke: Annotation<string>,
});
// Define node functions
// First LLM call to generate initial joke
async function generateJoke(state: typeof StateAnnotation.State) {
const msg = await llm.invoke(`Write a short joke about ${state.topic}`);
return { joke: msg.content };
}
// Gate function to check if the joke has a punchline
function checkPunchline(state: typeof StateAnnotation.State) {
// Simple check - does the joke contain "?" or "!"
if (state.joke?.includes("?") || state.joke?.includes("!")) {
return "Pass";
}
return "Fail";
}
// Second LLM call to improve the joke
async function improveJoke(state: typeof StateAnnotation.State) {
const msg = await llm.invoke(
`Make this joke funnier by adding wordplay: ${state.joke}`
);
return { improvedJoke: msg.content };
}
// Third LLM call for final polish
async function polishJoke(state: typeof StateAnnotation.State) {
const msg = await llm.invoke(
`Add a surprising twist to this joke: ${state.improvedJoke}`
);
return { finalJoke: msg.content };
}
// Build workflow
const chain = new StateGraph(StateAnnotation)
.addNode("generateJoke", generateJoke)
.addNode("improveJoke", improveJoke)
.addNode("polishJoke", polishJoke)
.addEdge("__start__", "generateJoke")
.addConditionalEdges("generateJoke", checkPunchline, {
Pass: "improveJoke",
Fail: "__end__"
})
.addEdge("improveJoke", "polishJoke")
.addEdge("polishJoke", "__end__")
.compile();
// Invoke
const state = await chain.invoke({ topic: "cats" });
console.log("Initial joke:");
console.log(state.joke);
console.log("\n--- --- ---\n");
if (state.improvedJoke !== undefined) {
console.log("Improved joke:");
console.log(state.improvedJoke);
console.log("\n--- --- ---\n");
console.log("Final joke:");
console.log(state.finalJoke);
} else {
console.log("Joke failed quality gate - no punchline detected!");
}
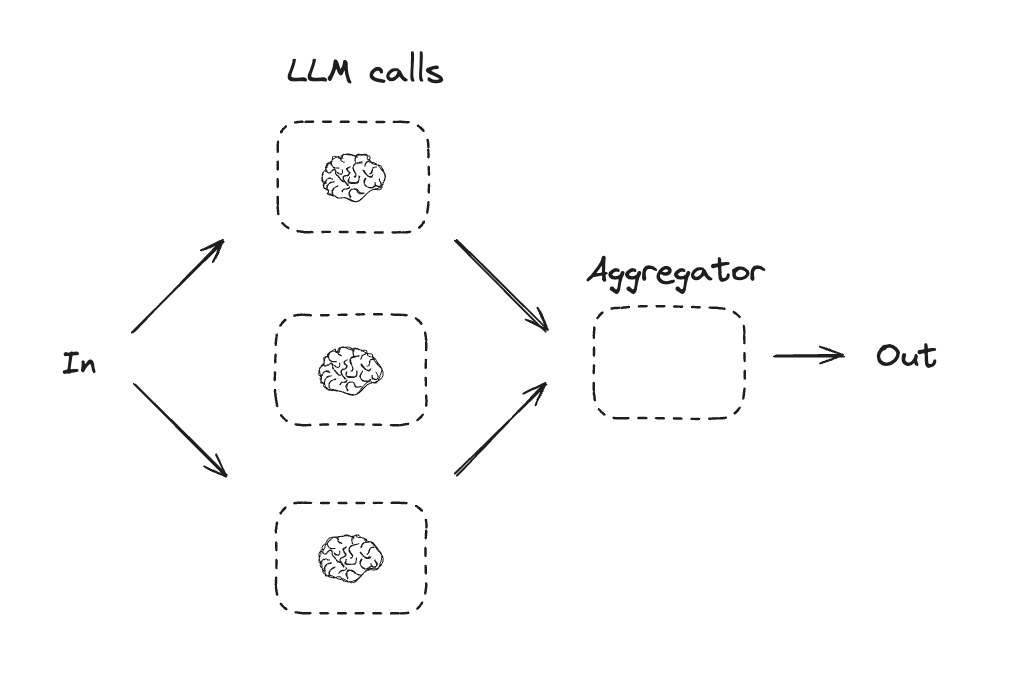
并行化
通过并行化,大型语言模型同时处理一项任务。这可以通过同时运行多个独立的子任务,或者多次运行同一任务以检查不同的输出。并行化通常用于:- 拆分子任务并并行运行它们,从而提高速度
- 多次运行任务以检查不同的输出,从而提高置信度
- 运行一个子任务处理文档以获取关键词,另一个子任务检查格式错误
- 多次运行一个任务,根据不同标准(例如引用数量、使用来源数量和来源质量)对文档进行准确性评分
复制
向 AI 提问
import { StateGraph, Annotation } from "@langchain/langgraph";
// Graph state
const StateAnnotation = Annotation.Root({
topic: Annotation<string>,
joke: Annotation<string>,
story: Annotation<string>,
poem: Annotation<string>,
combinedOutput: Annotation<string>,
});
// Nodes
// First LLM call to generate initial joke
async function callLlm1(state: typeof StateAnnotation.State) {
const msg = await llm.invoke(`Write a joke about ${state.topic}`);
return { joke: msg.content };
}
// Second LLM call to generate story
async function callLlm2(state: typeof StateAnnotation.State) {
const msg = await llm.invoke(`Write a story about ${state.topic}`);
return { story: msg.content };
}
// Third LLM call to generate poem
async function callLlm3(state: typeof StateAnnotation.State) {
const msg = await llm.invoke(`Write a poem about ${state.topic}`);
return { poem: msg.content };
}
// Combine the joke, story and poem into a single output
async function aggregator(state: typeof StateAnnotation.State) {
const combined = `Here's a story, joke, and poem about ${state.topic}!\n\n` +
`STORY:\n${state.story}\n\n` +
`JOKE:\n${state.joke}\n\n` +
`POEM:\n${state.poem}`;
return { combinedOutput: combined };
}
// Build workflow
const parallelWorkflow = new StateGraph(StateAnnotation)
.addNode("callLlm1", callLlm1)
.addNode("callLlm2", callLlm2)
.addNode("callLlm3", callLlm3)
.addNode("aggregator", aggregator)
.addEdge("__start__", "callLlm1")
.addEdge("__start__", "callLlm2")
.addEdge("__start__", "callLlm3")
.addEdge("callLlm1", "aggregator")
.addEdge("callLlm2", "aggregator")
.addEdge("callLlm3", "aggregator")
.addEdge("aggregator", "__end__")
.compile();
// Invoke
const result = await parallelWorkflow.invoke({ topic: "cats" });
console.log(result.combinedOutput);
路由
路由工作流处理输入,然后将其定向到特定于上下文的任务。这允许您为复杂任务定义专门的流程。例如,一个旨在回答产品相关问题的工作流可能会首先处理问题类型,然后将请求路由到定价、退款、退货等特定流程。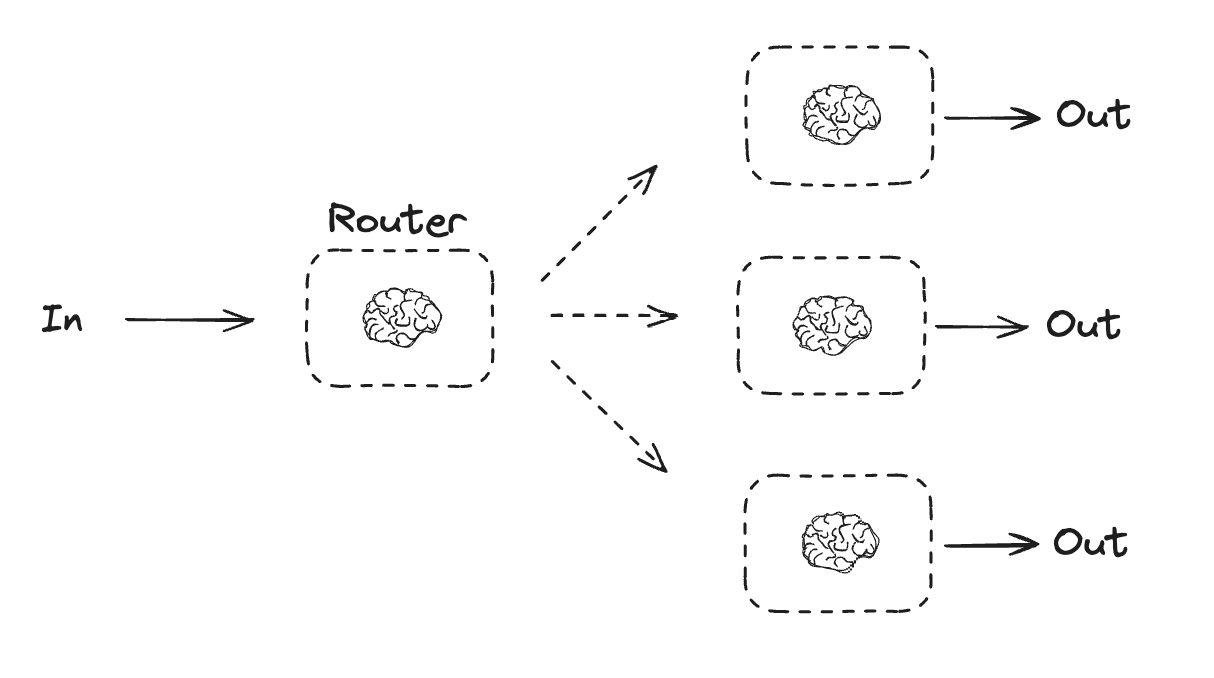
复制
向 AI 提问
import { StateGraph, Annotation } from "@langchain/langgraph";
import * as z from "zod";
// Schema for structured output to use as routing logic
const routeSchema = z.object({
step: z.enum(["poem", "story", "joke"]).describe(
"The next step in the routing process"
),
});
// Augment the LLM with schema for structured output
const router = llm.withStructuredOutput(routeSchema);
// Graph state
const StateAnnotation = Annotation.Root({
input: Annotation<string>,
decision: Annotation<string>,
output: Annotation<string>,
});
// Nodes
// Write a story
async function llmCall1(state: typeof StateAnnotation.State) {
const result = await llm.invoke([{
role: "system",
content: "You are an expert storyteller.",
}, {
role: "user",
content: state.input
}]);
return { output: result.content };
}
// Write a joke
async function llmCall2(state: typeof StateAnnotation.State) {
const result = await llm.invoke([{
role: "system",
content: "You are an expert comedian.",
}, {
role: "user",
content: state.input
}]);
return { output: result.content };
}
// Write a poem
async function llmCall3(state: typeof StateAnnotation.State) {
const result = await llm.invoke([{
role: "system",
content: "You are an expert poet.",
}, {
role: "user",
content: state.input
}]);
return { output: result.content };
}
async function llmCallRouter(state: typeof StateAnnotation.State) {
// Route the input to the appropriate node
const decision = await router.invoke([
{
role: "system",
content: "Route the input to story, joke, or poem based on the user's request."
},
{
role: "user",
content: state.input
},
]);
return { decision: decision.step };
}
// Conditional edge function to route to the appropriate node
function routeDecision(state: typeof StateAnnotation.State) {
// Return the node name you want to visit next
if (state.decision === "story") {
return "llmCall1";
} else if (state.decision === "joke") {
return "llmCall2";
} else if (state.decision === "poem") {
return "llmCall3";
}
}
// Build workflow
const routerWorkflow = new StateGraph(StateAnnotation)
.addNode("llmCall1", llmCall1)
.addNode("llmCall2", llmCall2)
.addNode("llmCall3", llmCall3)
.addNode("llmCallRouter", llmCallRouter)
.addEdge("__start__", "llmCallRouter")
.addConditionalEdges(
"llmCallRouter",
routeDecision,
["llmCall1", "llmCall2", "llmCall3"],
)
.addEdge("llmCall1", "__end__")
.addEdge("llmCall2", "__end__")
.addEdge("llmCall3", "__end__")
.compile();
// Invoke
const state = await routerWorkflow.invoke({
input: "Write me a joke about cats"
});
console.log(state.output);
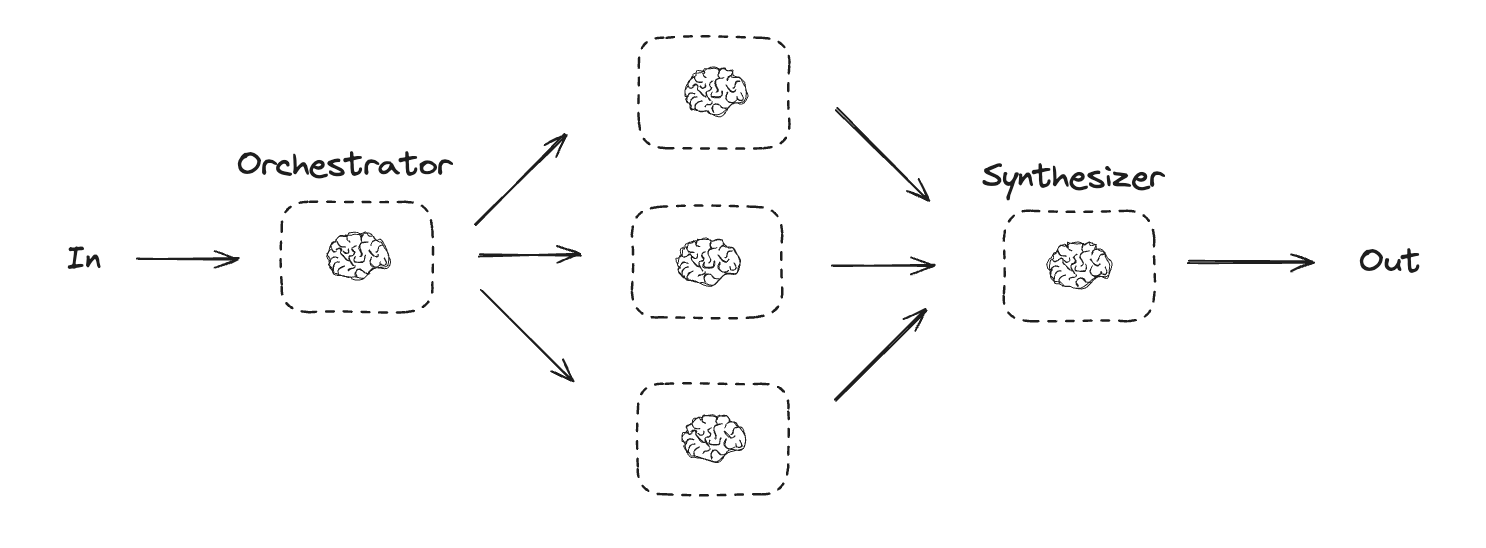
编排器-工作器
在编排器-工作器配置中,编排器- 将任务分解为子任务
- 将子任务委托给工作器
- 将工作器输出合成为最终结果
复制
向 AI 提问
type SectionSchema = {
name: string;
description: string;
}
type SectionsSchema = {
sections: SectionSchema[];
}
// Augment the LLM with schema for structured output
const planner = llm.withStructuredOutput(sectionsSchema);
在 LangGraph 中创建工作器
编排器-工作器工作流很常见,LangGraph 内置支持它们。`Send` API 允许您动态创建工作器节点并向它们发送特定输入。每个工作器都有自己的状态,所有工作器输出都写入一个共享状态键,编排器图可以访问该键。这使得编排器可以访问所有工作器输出,并将其合成为最终输出。以下示例迭代部分列表,并使用 `Send` API 将每个部分发送给一个工作器。复制
向 AI 提问
import { Annotation, StateGraph, Send } from "@langchain/langgraph";
// Graph state
const StateAnnotation = Annotation.Root({
topic: Annotation<string>,
sections: Annotation<SectionsSchema[]>,
completedSections: Annotation<string[]>({
default: () => [],
reducer: (a, b) => a.concat(b),
}),
finalReport: Annotation<string>,
});
// Worker state
const WorkerStateAnnotation = Annotation.Root({
section: Annotation<SectionsSchema>,
completedSections: Annotation<string[]>({
default: () => [],
reducer: (a, b) => a.concat(b),
}),
});
// Nodes
async function orchestrator(state: typeof StateAnnotation.State) {
// Generate queries
const reportSections = await planner.invoke([
{ role: "system", content: "Generate a plan for the report." },
{ role: "user", content: `Here is the report topic: ${state.topic}` },
]);
return { sections: reportSections.sections };
}
async function llmCall(state: typeof WorkerStateAnnotation.State) {
// Generate section
const section = await llm.invoke([
{
role: "system",
content: "Write a report section following the provided name and description. Include no preamble for each section. Use markdown formatting.",
},
{
role: "user",
content: `Here is the section name: ${state.section.name} and description: ${state.section.description}`,
},
]);
// Write the updated section to completed sections
return { completedSections: [section.content] };
}
async function synthesizer(state: typeof StateAnnotation.State) {
// List of completed sections
const completedSections = state.completedSections;
// Format completed section to str to use as context for final sections
const completedReportSections = completedSections.join("\n\n---\n\n");
return { finalReport: completedReportSections };
}
// Conditional edge function to create llm_call workers that each write a section of the report
function assignWorkers(state: typeof StateAnnotation.State) {
// Kick off section writing in parallel via Send() API
return state.sections.map((section) =>
new Send("llmCall", { section })
);
}
// Build workflow
const orchestratorWorker = new StateGraph(StateAnnotation)
.addNode("orchestrator", orchestrator)
.addNode("llmCall", llmCall)
.addNode("synthesizer", synthesizer)
.addEdge("__start__", "orchestrator")
.addConditionalEdges(
"orchestrator",
assignWorkers,
["llmCall"]
)
.addEdge("llmCall", "synthesizer")
.addEdge("synthesizer", "__end__")
.compile();
// Invoke
const state = await orchestratorWorker.invoke({
topic: "Create a report on LLM scaling laws"
});
console.log(state.finalReport);
评估器-优化器
在评估器-优化器工作流中,一次大型语言模型调用创建响应,另一次调用评估该响应。如果评估器或人工干预确定响应需要改进,则提供反馈并重新创建响应。此循环持续进行,直到生成可接受的响应。 评估器-优化器工作流通常用于任务有特定的成功标准,但需要迭代才能满足该标准的情况。例如,两种语言之间的文本翻译并非总是完美匹配。可能需要多次迭代才能生成在两种语言中具有相同含义的翻译。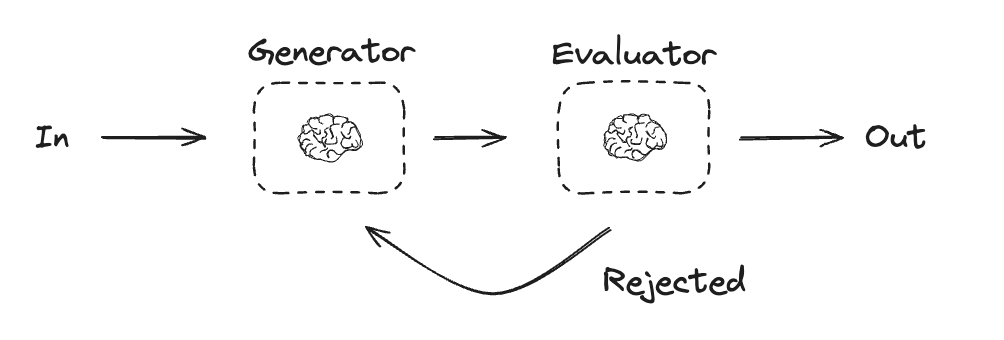
复制
向 AI 提问
import * as z from "zod";
import { Annotation, StateGraph } from "@langchain/langgraph";
// Graph state
const StateAnnotation = Annotation.Root({
joke: Annotation<string>,
topic: Annotation<string>,
feedback: Annotation<string>,
funnyOrNot: Annotation<string>,
});
// Schema for structured output to use in evaluation
const feedbackSchema = z.object({
grade: z.enum(["funny", "not funny"]).describe(
"Decide if the joke is funny or not."
),
feedback: z.string().describe(
"If the joke is not funny, provide feedback on how to improve it."
),
});
// Augment the LLM with schema for structured output
const evaluator = llm.withStructuredOutput(feedbackSchema);
// Nodes
async function llmCallGenerator(state: typeof StateAnnotation.State) {
// LLM generates a joke
let msg;
if (state.feedback) {
msg = await llm.invoke(
`Write a joke about ${state.topic} but take into account the feedback: ${state.feedback}`
);
} else {
msg = await llm.invoke(`Write a joke about ${state.topic}`);
}
return { joke: msg.content };
}
async function llmCallEvaluator(state: typeof StateAnnotation.State) {
// LLM evaluates the joke
const grade = await evaluator.invoke(`Grade the joke ${state.joke}`);
return { funnyOrNot: grade.grade, feedback: grade.feedback };
}
// Conditional edge function to route back to joke generator or end based upon feedback from the evaluator
function routeJoke(state: typeof StateAnnotation.State) {
// Route back to joke generator or end based upon feedback from the evaluator
if (state.funnyOrNot === "funny") {
return "Accepted";
} else if (state.funnyOrNot === "not funny") {
return "Rejected + Feedback";
}
}
// Build workflow
const optimizerWorkflow = new StateGraph(StateAnnotation)
.addNode("llmCallGenerator", llmCallGenerator)
.addNode("llmCallEvaluator", llmCallEvaluator)
.addEdge("__start__", "llmCallGenerator")
.addEdge("llmCallGenerator", "llmCallEvaluator")
.addConditionalEdges(
"llmCallEvaluator",
routeJoke,
{
// Name returned by routeJoke : Name of next node to visit
"Accepted": "__end__",
"Rejected + Feedback": "llmCallGenerator",
}
)
.compile();
// Invoke
const state = await optimizerWorkflow.invoke({ topic: "Cats" });
console.log(state.joke);
代理
代理通常被实现为使用工具执行动作的大型语言模型。它们在持续的反馈循环中运行,并用于问题和解决方案不可预测的情况。代理比工作流拥有更多的自主权,可以决定使用哪些工具以及如何解决问题。您仍然可以定义可用的工具集和代理行为的指导方针。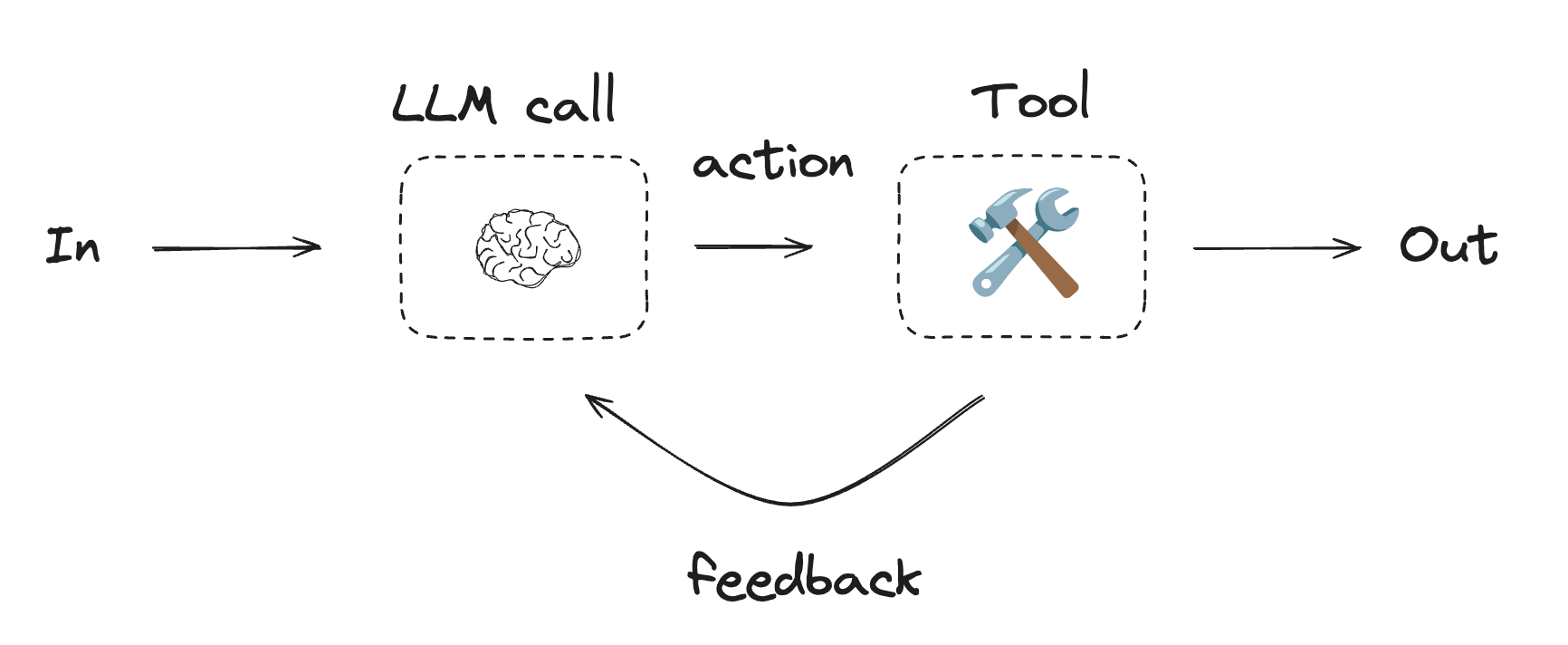
使用工具
复制
向 AI 提问
import { tool } from "@langchain/core/tools";
import * as z from "zod";
// Define tools
const multiply = tool(
({ a, b }) => {
return a * b;
},
{
name: "multiply",
description: "Multiply two numbers together",
schema: z.object({
a: z.number().describe("first number"),
b: z.number().describe("second number"),
}),
}
);
const add = tool(
({ a, b }) => {
return a + b;
},
{
name: "add",
description: "Add two numbers together",
schema: z.object({
a: z.number().describe("first number"),
b: z.number().describe("second number"),
}),
}
);
const divide = tool(
({ a, b }) => {
return a / b;
},
{
name: "divide",
description: "Divide two numbers",
schema: z.object({
a: z.number().describe("first number"),
b: z.number().describe("second number"),
}),
}
);
// Augment the LLM with tools
const tools = [add, multiply, divide];
const toolsByName = Object.fromEntries(tools.map((tool) => [tool.name, tool]));
const llmWithTools = llm.bindTools(tools);
复制
向 AI 提问
import { MessagesAnnotation, StateGraph } from "@langchain/langgraph";
import { ToolNode } from "@langchain/langgraph/prebuilt";
import {
SystemMessage,
ToolMessage
} from "@langchain/core/messages";
// Nodes
async function llmCall(state: typeof MessagesAnnotation.State) {
// LLM decides whether to call a tool or not
const result = await llmWithTools.invoke([
{
role: "system",
content: "You are a helpful assistant tasked with performing arithmetic on a set of inputs."
},
...state.messages
]);
return {
messages: [result]
};
}
const toolNode = new ToolNode(tools);
// Conditional edge function to route to the tool node or end
function shouldContinue(state: typeof MessagesAnnotation.State) {
const messages = state.messages;
const lastMessage = messages.at(-1);
// If the LLM makes a tool call, then perform an action
if (lastMessage?.tool_calls?.length) {
return "toolNode";
}
// Otherwise, we stop (reply to the user)
return "__end__";
}
// Build workflow
const agentBuilder = new StateGraph(MessagesAnnotation)
.addNode("llmCall", llmCall)
.addNode("toolNode", toolNode)
// Add edges to connect nodes
.addEdge("__start__", "llmCall")
.addConditionalEdges(
"llmCall",
shouldContinue,
["toolNode", "__end__"]
)
.addEdge("toolNode", "llmCall")
.compile();
// Invoke
const messages = [{
role: "user",
content: "Add 3 and 4."
}];
const result = await agentBuilder.invoke({ messages });
console.log(result.messages);
以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。