

自托管版本要求访问警报需要 Helm chart 版本 0.10.3 或更高。
概览
LLM 应用程序中的有效可观测性需要主动检测故障、性能下降和回归。LangSmith 的警报功能有助于识别关键问题,例如:- 来自模型提供商的 API 速率限制违规
- 应用程序的延迟增加
- 影响反映最终用户体验的反馈分数的应用程序更改
配置警报
步骤 1:导航到创建警报
首先导航到您要为其配置警报的追踪项目。单击页面右上角的警报图标,查看该项目的现有警报并设置新警报。步骤 2:选择指标类型
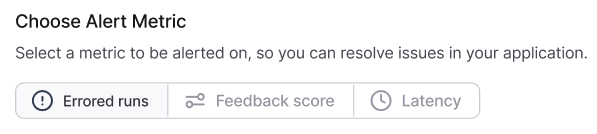
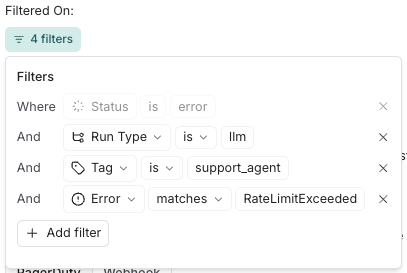
此外,对于错误运行和运行延迟,您可以定义过滤器以缩小触发警报的运行范围。例如,您可以为所有标记为
support_agent并遇到RateLimitExceeded错误的llm运行创建错误警报过滤器。
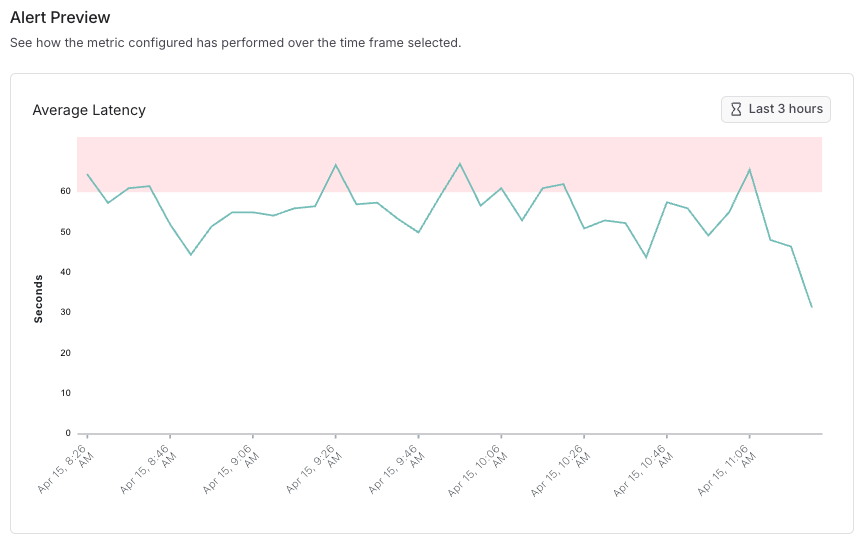
步骤 2:定义警报条件
警报条件由以下几个组件组成- 聚合方法:平均值、百分比或计数
- 比较运算符:
>=、<=或超过阈值 - 阈值:触发警报的数值
- 聚合窗口:指标计算的时间段(目前可在 5 或 15 分钟之间选择)
- 反馈键(仅限反馈分数警报):要监控的特定反馈指标

步骤 3:配置通知渠道
LangSmith 支持以下通知渠道 选择适当的渠道以确保通知到达负责的团队成员。最佳实践
- 根据应用程序的关键性调整灵敏度
- 从更宽泛的阈值开始,并根据观察到的模式进行细化
- 确保警报路由到达适当的待命人员
以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。