

在线评估可为您生产中的跟踪提供实时反馈。这对于持续监控应用程序的性能非常有用——以识别问题、衡量改进并确保随着时间的推移保持一致的质量。 LangSmith 支持两种类型的在线评估:
- LLM-as-a-judge:使用 LLM 评估跟踪,作为人类判断的可扩展替代方案(例如,毒性、幻觉、正确性)。支持两种不同粒度级别
- 运行级别:评估单个运行。
- 线程级别:评估线程中的所有跟踪。
- 自定义代码:直接在 LangSmith 中用 Python 编写评估器。通常用于验证数据的结构或统计属性。
当在线评估器对跟踪中的任何运行进行评估时,该跟踪将自动升级到扩展数据保留。此升级将影响跟踪定价,但可确保符合您评估标准(通常是那些最有价值的分析)的跟踪得到保留以供调查。
查看在线评估器
转到跟踪项目选项卡并选择一个跟踪项目。要查看该项目的现有在线评估器,请单击评估器选项卡。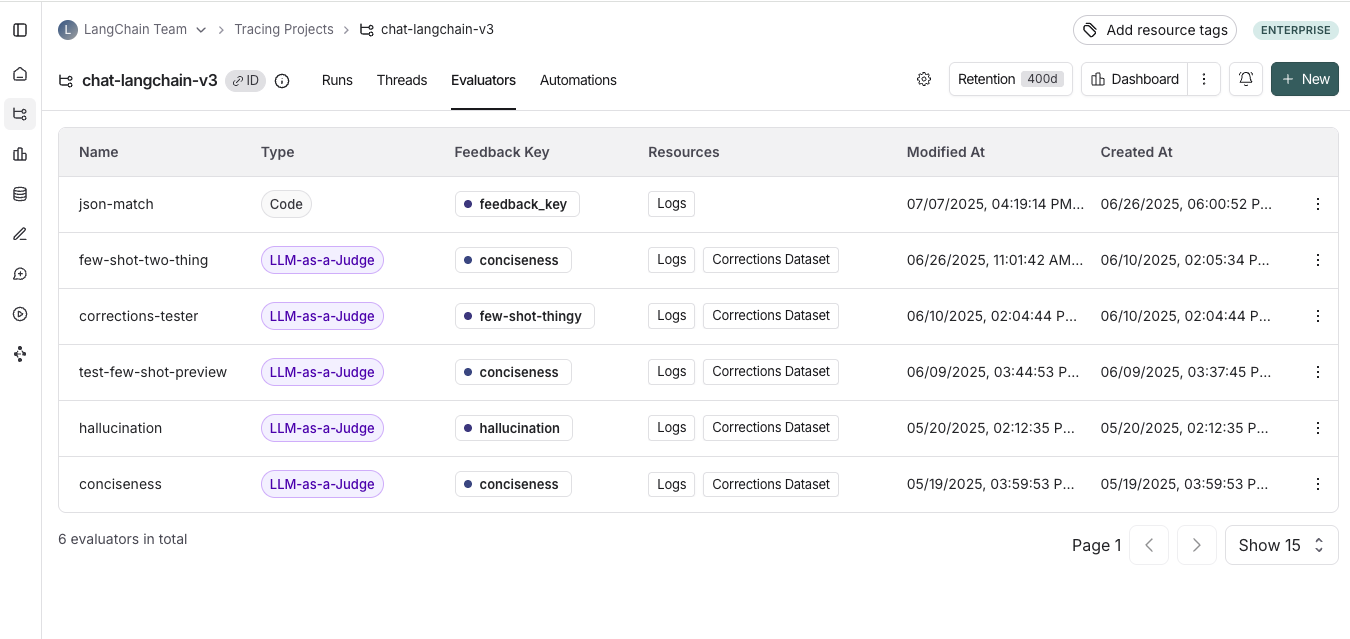
配置在线评估器
1. 导航到在线评估器
转到跟踪项目选项卡并选择一个跟踪项目。单击跟踪项目页面右上角的 + 新建,然后单击新建评估器。选择您要配置的评估器。2. 命名您的评估器
3. 创建过滤器
例如,您可能希望根据以下条件应用特定的评估器:- 用户留下反馈表示响应不满意时的运行。
- 调用特定工具的运行。有关更多信息,请参阅过滤工具调用。
- 与特定元数据匹配的运行(例如,如果您使用`plan_type`记录跟踪,并且只想对来自企业客户的跟踪运行评估)。有关更多信息,请参阅向跟踪添加元数据。
在为评估器创建过滤器时,检查运行通常很有帮助。在评估器配置面板打开的情况下,您可以检查运行并对其应用过滤器。您应用于运行表的任何过滤器将自动反映在评估器上的过滤器中。
4. (可选)配置采样率
配置采样率以控制触发自动化操作的过滤运行的百分比。例如,为了控制成本,您可能希望设置一个过滤器,仅将评估器应用于 10% 的跟踪。为此,您需要将采样率设置为 0.1。5. (可选)将规则应用于过去的运行
通过切换应用于过去的运行并输入“回填自”日期,将规则应用于过去的运行。这只有在规则创建时才可能实现。注意:回填作为后台作业处理,因此您不会立即看到结果。 为了跟踪回填进度,您可以通过导航到跟踪项目中的评估器选项卡并单击所创建评估器的“日志”按钮来查看评估器的日志。在线评估器日志与自动化规则日志类似。- 添加评估器名称
- (可选)过滤您希望评估器应用到的运行或配置采样率。
- 选择应用评估器
6. 选择评估器类型
配置 LLM-as-a-judge 在线评估器
查看本指南以配置 LLM-as-a-judge 评估器。配置自定义代码评估器
选择自定义代码评估器。编写评估函数
自定义代码评估器限制。允许的库:您可以导入所有标准库函数,以及以下公共包:网络访问:您无法从自定义代码评估器访问互联网。
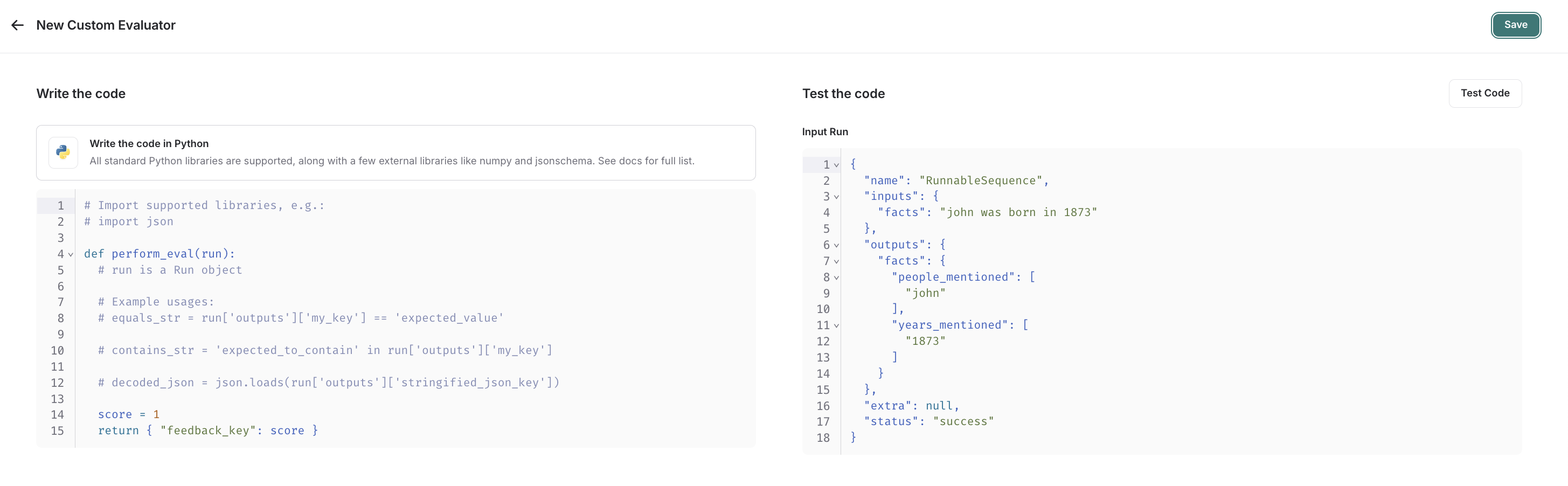
- 一个
Run(参考)。这表示要评估的采样运行。
- 反馈字典:一个字典,其键是您希望返回的反馈类型,值是您将为该反馈键提供的分数。例如,
{"correctness": 1, "silliness": 0}将在运行上创建两种类型的反馈,一种表示其正确,另一种表示其不傻。
测试并保存评估函数
在保存之前,您可以通过单击测试代码来在最近的运行上测试您的评估器函数,以确保您的代码正常执行。 一旦您保存,您的在线评估器将对新采样的运行(如果您选择了回填选项,也会对回填的运行)执行。 如果您喜欢视频教程,请查看 LangSmith 简介课程中的在线评估视频。视频指南
配置多轮在线评估器
多轮在线评估器允许您评估人类与代理之间的整个对话——而不仅仅是单个交流。它们衡量跨线程中所有轮次端到端交互质量。 您可以使用多轮评估来衡量:- 语义意图:用户想要做什么。
- 语义结果:实际发生了什么,任务是否成功。
- 轨迹:对话如何展开,包括工具调用的轨迹。
运行多轮在线评估将自动将线程中的每个跟踪升级到扩展数据保留。此升级将影响跟踪定价,但可确保符合您评估标准(通常是那些最有价值的分析)的跟踪得到保留以供调查。
先决条件
- 您的跟踪项目必须使用线程。
- 线程中每个跟踪的顶级输入和输出必须包含一个包含消息列表的
messages键。我们支持 LangChain、OpenAI Chat Completions 和 Anthropic Messages 格式的消息。- 如果每个跟踪的顶级输入和输出只包含对话中的最新消息,LangSmith 将自动将跨回合的消息组合成一个线程。
- 如果每个跟踪的顶级输入和输出包含完整的对话历史记录,LangSmith 将直接使用该历史记录。
如果您的跟踪不符合上述格式,线程级评估器将不起作用。您需要更新向 LangSmith 跟踪的方式,以确保每个跟踪的顶级输入和输出都包含一个
messages 列表。请参阅故障排除部分了解更多信息。配置
- 导航到跟踪项目选项卡并选择一个跟踪项目。
- 点击跟踪项目页面右上角的 + 新建 > 新建评估器 > 评估多轮线程。
- 命名您的评估器.
- 应用过滤器或采样率.
使用过滤器或采样来控制评估器成本。例如,仅评估N轮以下的线程或采样所有线程的10%。 - 配置空闲时间.
首次配置线程级评估器时,您将定义空闲时间——即线程中最后一次跟踪后,被视为完成并可进行评估的时间。此值应反映应用程序中用户交互的预期长度。它适用于项目中的所有评估器。
首次测试评估器时,请使用较短的空闲时间,以便快速查看结果。验证后,将其增加以匹配用户交互的预期长度。
-
配置您的模型。
选择要用于评估器的提供商和模型。线程往往会很长,因此您应该使用具有更高上下文窗口的模型,以避免超出限制。例如,OpenAI 的 GPT-4.1 mini 或 Gemini 2.5 Flash 都是不错的选择,因为它们都具有 1M+ 令牌上下文窗口。 -
配置 LLM-as-a-judge 提示。
定义您要评估的内容。此提示将用于评估线程。您还可以配置messages列表的哪些部分传递给评估器,以控制其接收的内容- 所有消息:发送完整的消息列表。
- 人类与AI对话:只发送用户和助手消息(不包括系统消息、工具调用等)。
- 第一个人类消息和最后一个 AI 消息:仅发送第一个用户消息和最后一个助手回复。
-
设置您的反馈配置.
配置反馈键的名称、您要收集的反馈格式,并可选地启用对反馈的推理。
我们不建议对线程级评估器和运行级评估器使用相同的反馈键,因为这可能难以区分。
- 保存您的评估器。
限制
这些是多轮在线评估器的当前限制(可能会更改)。如果您遇到任何这些限制,请与我们联系。- 运行必须在七天内:当一个线程空闲时,只有过去 7 天内的运行才有资格进行评估。
- 一次最多评估 500 个线程:如果在五分钟内有超过 500 个线程被标记为闲置,我们将自动对超过 500 个的线程进行采样。
- 每个工作区最多可有 10 个多轮在线评估器
故障排除
检查评估器状态您可以通过导航到跟踪项目中的评估器选项卡,并单击所创建评估器的日志按钮来查看其运行历史记录,从而检查评估器上次运行的时间。 检查发送给评估器的数据
通过导航到跟踪项目中的评估器选项卡,单击您创建的评估器,然后单击评估器跟踪选项卡,检查发送给评估器的数据。 在此选项卡中,您可以看到传递给 LLM-as-a-judge 评估器的输入。如果您的消息未正确传递,您将在输入中看到空白值。这可能发生在您的消息未采用预期格式之一的情况下。
以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。