

先决条件
- 一个 OpenAI API 密钥(在此处生成)或一个 Anthropic API 密钥(在此处生成)
- 在 LangSmith 中创建规则的权限(生成新的 Insights 报告所需)
- 在 LangSmith 中查看跟踪项目的权限(查看现有 Insights 报告所需)
生成您的第一个洞察报告
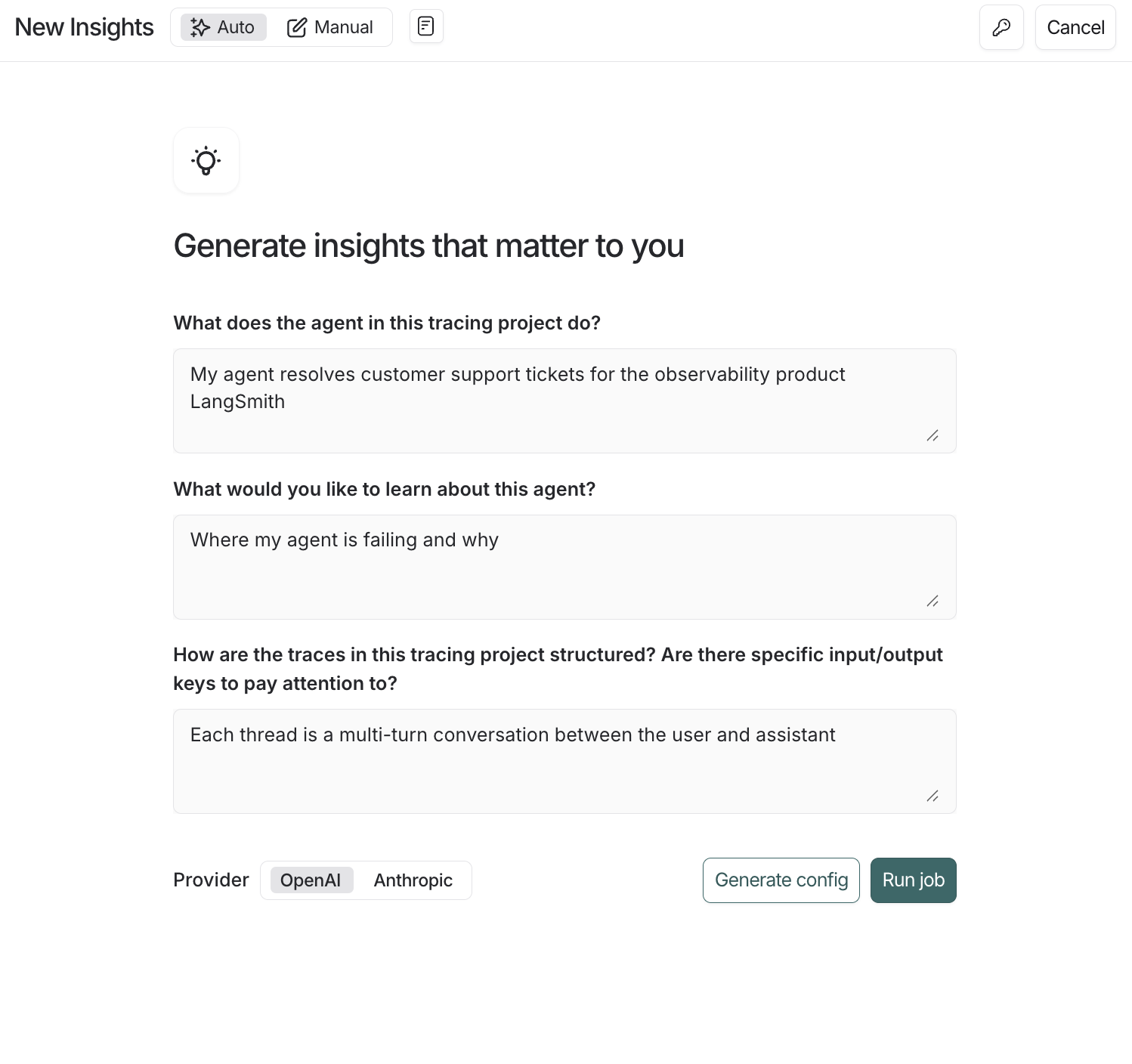
Insights Agent 的自动配置流程
- 导航到左侧菜单中的 Tracing Projects,然后选择一个跟踪项目。
- 点击右上角的 +New,然后点击 New Insights Report,为该项目生成新的洞察。
- 输入作业名称。
- 点击作业创建窗格右上角的图标,将您的 OpenAI(或 Anthropic)API 密钥设置为工作区秘密。如果您的工作区已设置 OpenAI API 密钥,则可以跳过此步骤。
- 回答引导问题,将您的 Insights 报告重点放在您想了解的代理方面,然后点击 Run job。
使用 OpenAI 模型生成 1,000 个线程的洞察通常花费 1.00-2.00 美元,使用当前的 Anthropic 模型花费 3.00-4.00 美元。成本随着采样线程的数量和每个线程的大小而变化。
理解结果
作业完成后,您可以导航到 Insights 选项卡,在那里您将看到一个 Insights 报告表。每个报告都包含从跟踪项目中特定轨迹样本生成的洞察。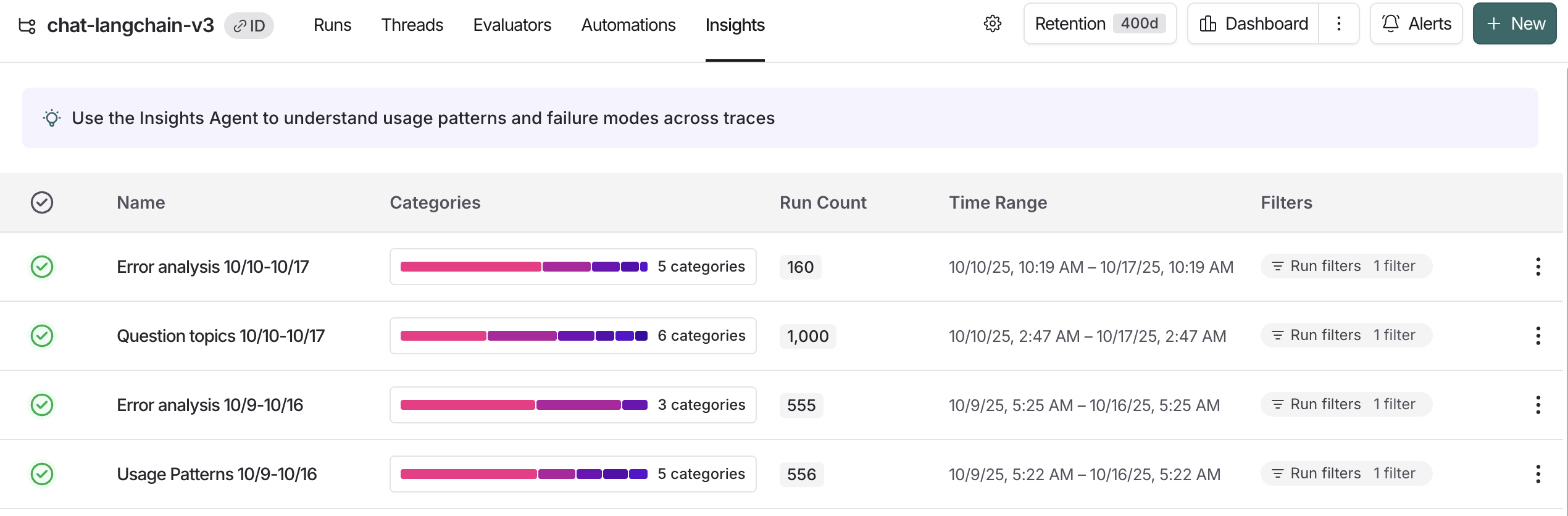
单个跟踪项目的洞察报告
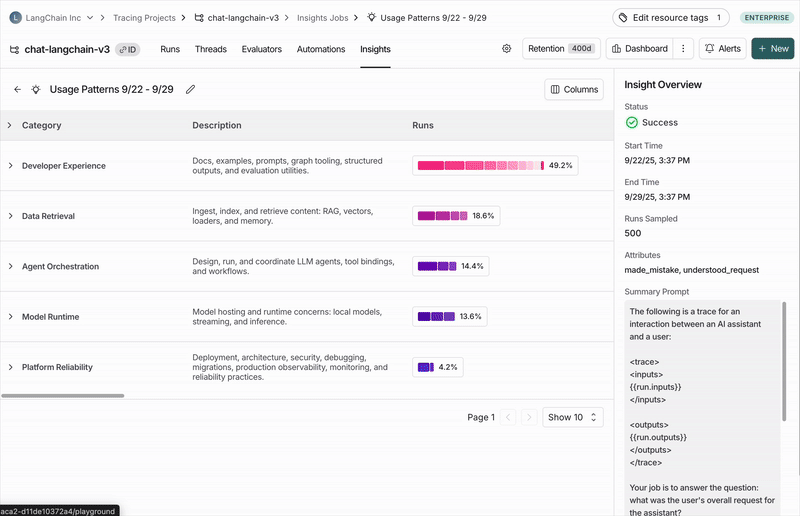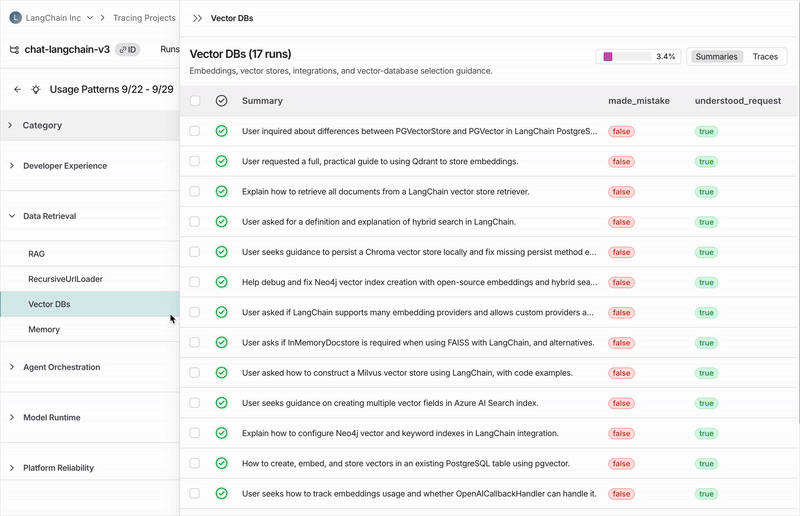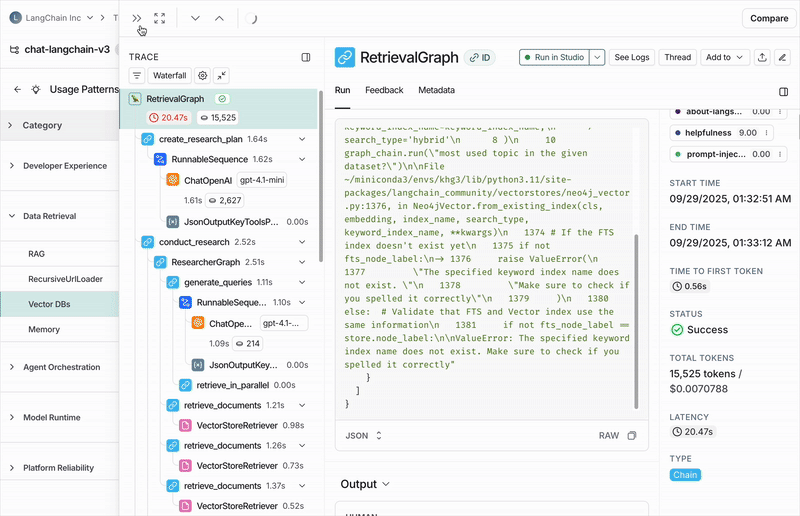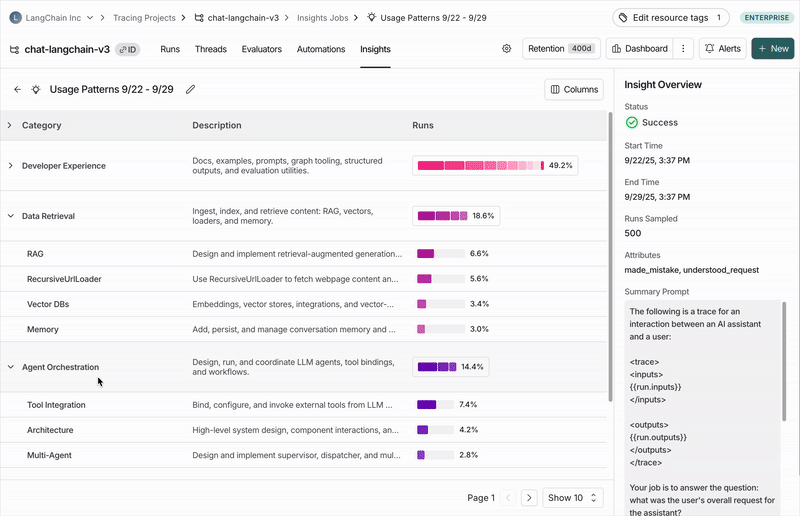
与 https://chat.langchain.com 聊天机器人进行对话的常见主题
顶级类别
您的轨迹会自动分组为顶级类别,代表数据中最广泛的模式。 分布条显示了每种模式发生的频率,使得很容易发现比预期发生得多或少的行为。 每个类别都有一个简短的描述,并显示其包含的轨迹的聚合指标,包括:- 典型轨迹统计(如错误率、延迟、成本)
- 评估员的反馈分数
- 作为作业一部分提取的属性
子类别
点击任何类别都会显示细分为子类别,这让您对该类别轨迹中的交互模式有更细致的理解。 在上面图示的 Chat Langchain 示例中,“数据与检索”下有“向量存储”和“数据摄取”等子类别。单个轨迹
您可以通过点击查看轨迹表来查看分配给每个类别或子类别的轨迹。从那里,您可以点击任何轨迹以查看完整的对话详情。配置作业
您可以通过三种方式创建洞察报告。从自动生成流程开始,以建立基线,然后随着您的完善,使用保存的或手动配置进行迭代。自动生成配置
- 打开 New Insights 并确保 Auto 切换按钮处于活动状态。
- 回答关于代理目的、您想了解什么以及轨迹结构方式的自然语言问题。Insights 会将您的答案转换为草稿配置(作业名称、摘要提示、属性和采样默认值)。
- 选择提供商,然后点击 Generate config 预览或 Run job 立即启动。
选择模型提供商
您可以选择 OpenAI 或 Anthropic 模型来驱动代理。您必须为您选择的任何提供商设置相应的工作区秘密(OPENAI_API_KEY 或 ANTHROPIC_API_KEY)。 请注意,使用当前的 Anthropic 模型成本大约是使用 OpenAI 模型的 3 倍。使用预构建配置
使用 Saved configurations 下拉菜单加载常见作业的预设,例如 Usage Patterns 或 Error Analysis。直接运行它们以快速启动,或者在保存自定义版本之前调整过滤器、提示和提供商。要了解有关可自定义内容的更多信息,请阅读下面的部分。从头开始构建配置
当您需要更多控制时(例如,预定义您希望数据分组到的类别,或定位与特定反馈分数和过滤器匹配的轨迹),构建自己的配置会很有帮助。选择轨迹
- 样本大小:要分析的最大轨迹数。目前上限为 1,000
- 时间范围:从该时间范围采样轨迹
- 过滤器:其他轨迹过滤器。当您调整过滤器时,您将看到有多少轨迹符合您的标准
类别
默认情况下,顶级类别是从底层轨迹自动自下而上生成的。在某些情况下,您预先知道您感兴趣的特定类别,并希望作业将轨迹分类到这些预定义类别中。 配置的 Categories 部分允许您通过枚举您希望使用的顶级类别的名称和描述来实现此目的。子类别仍由算法在预定义的顶级类别中自动生成。摘要提示
作业的第一步是创建每个轨迹的简要摘要——然后将这些摘要进行分类。在摘要中提取正确的信息对于获得有用的类别至关重要。用于生成这些摘要的提示可以进行编辑。 编辑提示时要考虑的两件事是:- 摘要说明:摘要中未包含的任何信息都不会影响生成的类别,因此请务必提供清晰的说明,说明要从每个轨迹中提取哪些重要信息。
- 轨迹内容:使用 mustache 格式指定轨迹的哪些部分传递给摘要器。包含大量输入和输出的大型轨迹可能成本高昂且嘈杂。将提示缩小到只包含轨迹中最相关的部分可以改善您的结果。
| 变量 | 最适合 | 示例 |
|---|---|---|
| run.* | 访问线程中最新根运行(即最后一轮)的数据 | {{run.inputs}} {{run.outputs}} {{run.error}} |
"Summarize this: {{run.inputs.foo.bar}}" 将只包含上次运行输入中“foo”值内的“bar”值。
属性
除了摘要之外,您还可以定义要从每个轨迹中提取的附加分类、数值和布尔属性。这些属性将影响分类步骤——具有相似属性值的轨迹倾向于被归为一类。您还可以按类别查看这些属性的聚合。 例如,您可能希望从每个轨迹中提取属性user_satisfied: boolean,以引导算法将积极和消极的用户体验分开的类别,并查看每个类别的平均用户满意度。过滤属性
您可以使用布尔属性上的filter_by 参数在生成洞察之前预过滤轨迹。启用后,只有属性评估为 true 的轨迹才包含在分析中。 当您希望将洞察报告集中在轨迹的特定子集时,这非常有用——例如,只分析错误,只检查英语对话,或者只包含满足特定质量标准的轨迹。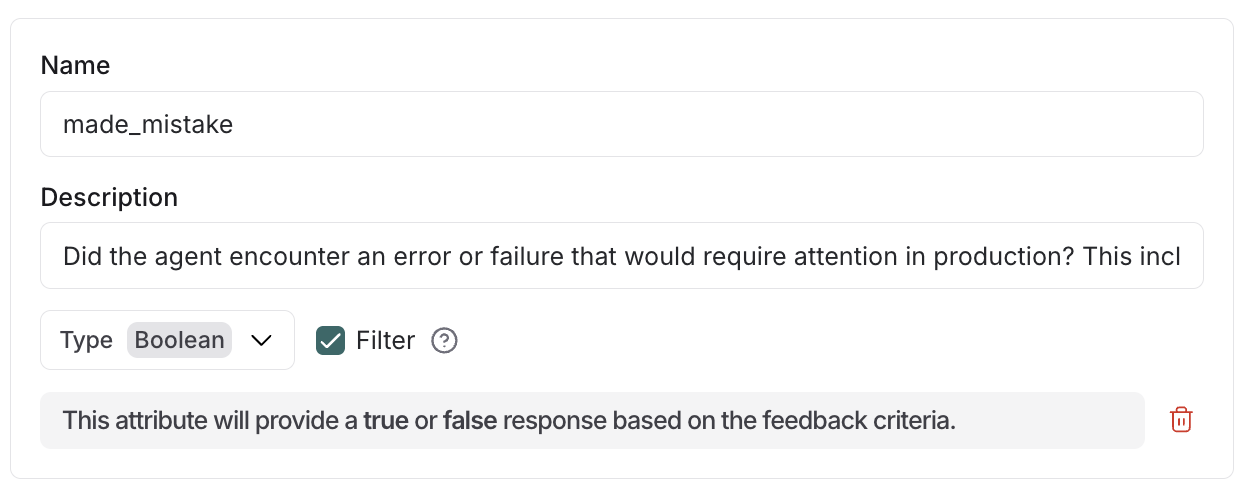
使用过滤器属性仅生成带有代理错误的轨迹的洞察
- 在为 Insights Agent 创建配置时,将
"filter_by": true添加到任何布尔属性 - LLM 在摘要过程中根据属性描述评估每个轨迹
- 在生成洞察之前,将排除属性为
false或缺失的轨迹
保存您的配置
您可以选择使用“另存为”按钮保存配置以备将来重用。如果您希望随着时间推移比较洞察报告以识别用户和代理行为的变化,这尤其有用。 在创建新的洞察报告时,从窗格左上角的下拉菜单中选择以前保存的配置。以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。