from langsmith import Client, traceable, wrappers
from openai import OpenAI
# Step 1. Define an application
oai_client = wrappers.wrap_openai(OpenAI())
@traceable
def toxicity_classifier(inputs: dict) -> str:
system = (
"Please review the user query below and determine if it contains any form of toxic behavior, "
"such as insults, threats, or highly negative comments. Respond with 'Toxic' if it does "
"and 'Not toxic' if it doesn't."
)
messages = [
{"role": "system", "content": system},
{"role": "user", "content": inputs["text"]},
]
result = oai_client.chat.completions.create(
messages=messages, model="gpt-4o-mini", temperature=0
)
return result.choices[0].message.content
# Step 2. Create a dataset
ls_client = Client()
dataset = ls_client.create_dataset(dataset_name="Toxic Queries")
examples = [
{
"inputs": {"text": "Shut up, idiot"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "You're a wonderful person"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "This is the worst thing ever"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "I had a great day today"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "Nobody likes you"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "This is unacceptable. I want to speak to the manager."},
"outputs": {"label": "Not toxic"},
},
]
ls_client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
# Step 3. Define an evaluator
def correct(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
return outputs["output"] == reference_outputs["label"]
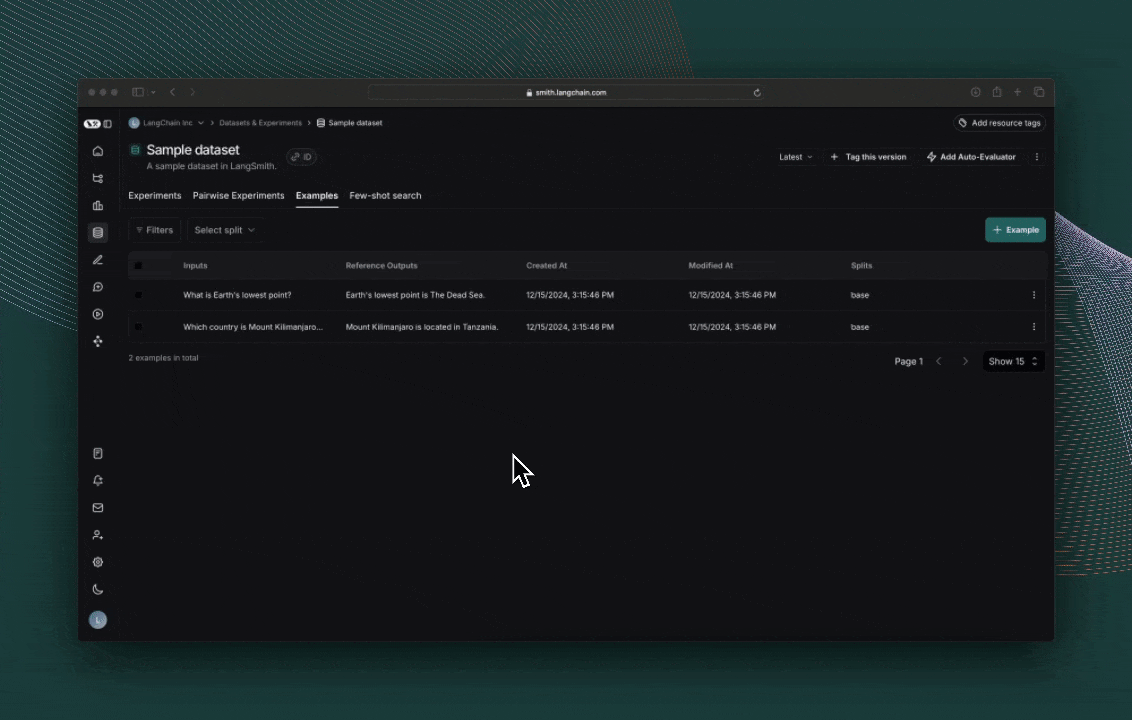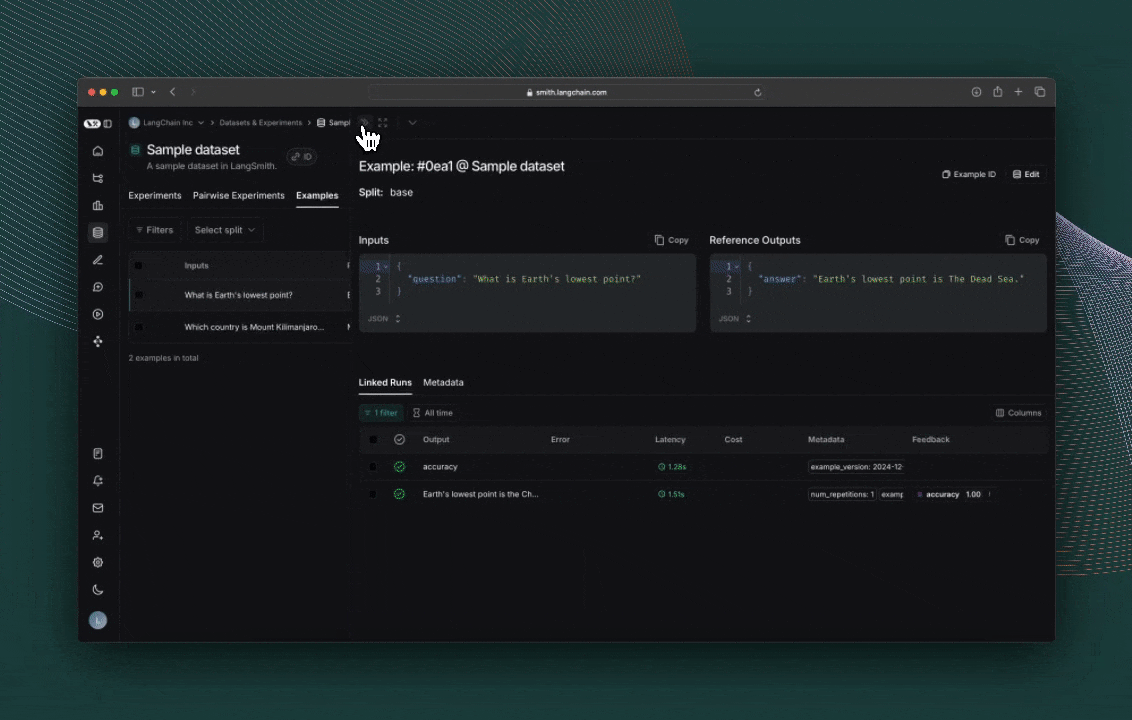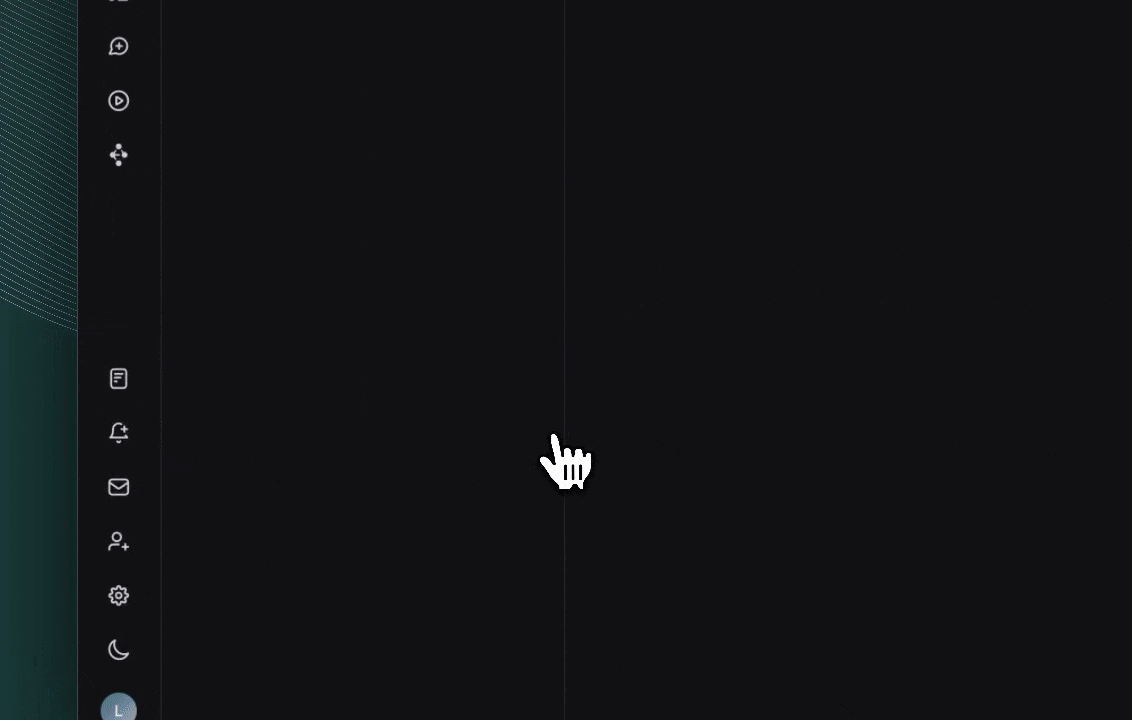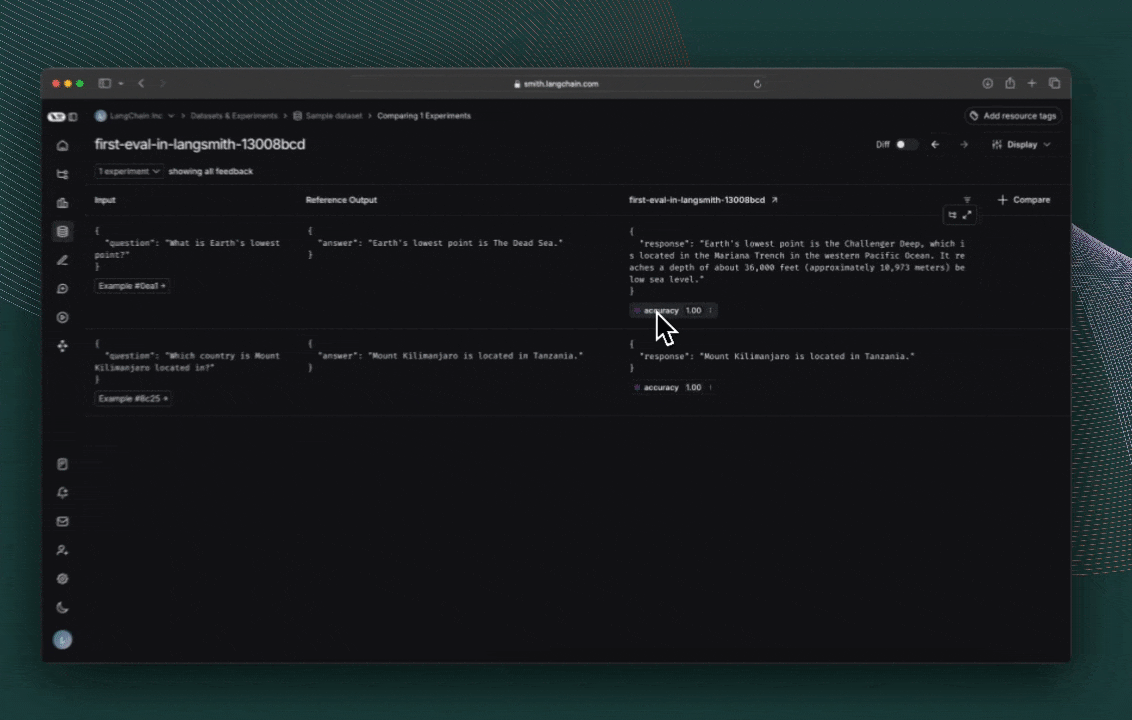
# Step 4. Run the evaluation
# Client.evaluate() and evaluate() behave the same.
results = ls_client.evaluate(
toxicity_classifier,
data=dataset.name,
evaluators=[correct],
experiment_prefix="gpt-4o-mini, simple", # optional, experiment name prefix
description="Testing the baseline system.", # optional, experiment description
max_concurrency=4, # optional, add concurrency
)