

本操作指南将演示如何设置和运行一种评估器(LLM-as-a-judge)。有关预构建评估器的完整列表和使用示例,请参阅 openevals 和 agentevals 仓库。
设置
你需要安装openevals 包才能使用预构建的 LLM-as-a-judge 评估器。
openevals 也与 evaluate 方法无缝集成。有关设置说明,请参阅相应的指南。
运行评估器
一般流程很简单:从openevals 导入评估器或工厂函数,然后在你的测试文件中使用输入、输出和参考输出来运行它。LangSmith 将自动把评估器的结果记录为反馈。 请注意,并非所有评估器都需要每个参数(例如,精确匹配评估器只需要输出和参考输出)。此外,如果你的 LLM-as-a-judge 提示需要额外的变量,将其作为 kwargs 传入将把它们格式化到提示中。 像这样设置你的测试文件:feedback_key/feedbackKey 参数将用作你实验中反馈的名称。 在你的终端中运行评估将得到类似以下结果: 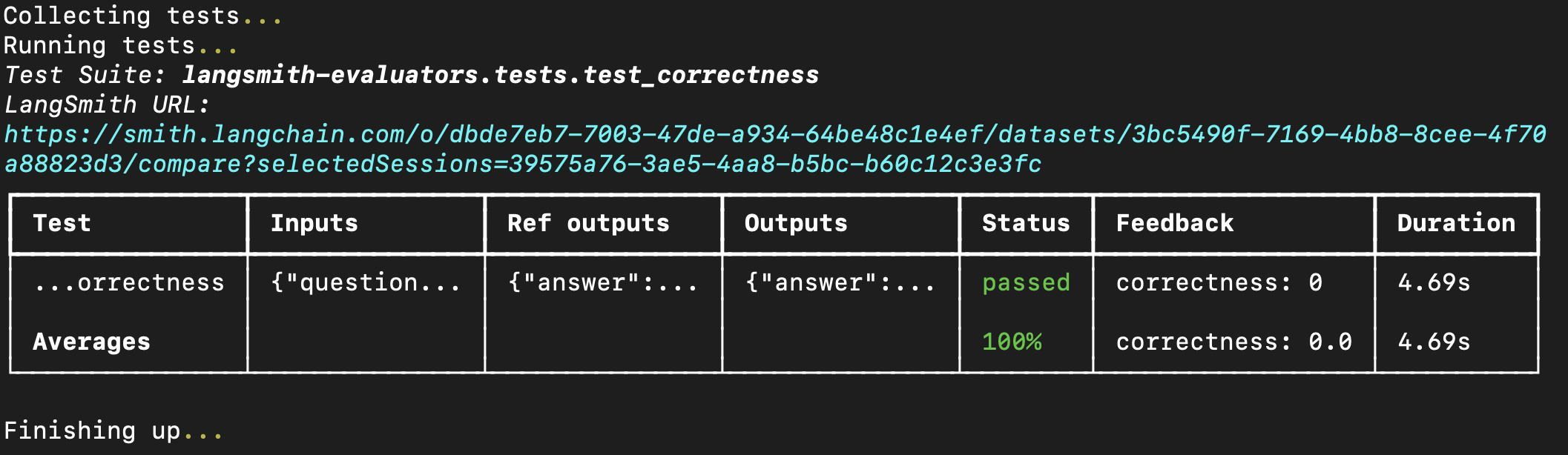
evaluate 方法。如果使用 Python,这需要 langsmith>=0.3.11:以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。