inputs = { "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Hi, can you tell me the capital of France?" } ] } ]}outputs = { "messages": [ { "role": "assistant", "content": [ { "type": "text", "text": "The capital of France is Paris." }, { "type": "reasoning", "text": "The user is asking about..." } ] } ]}
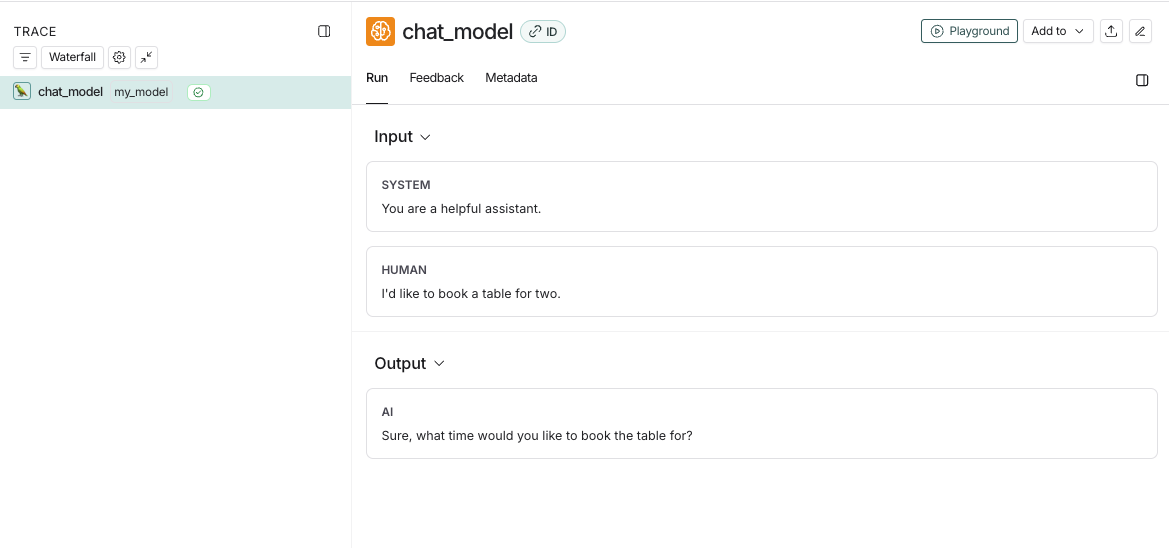
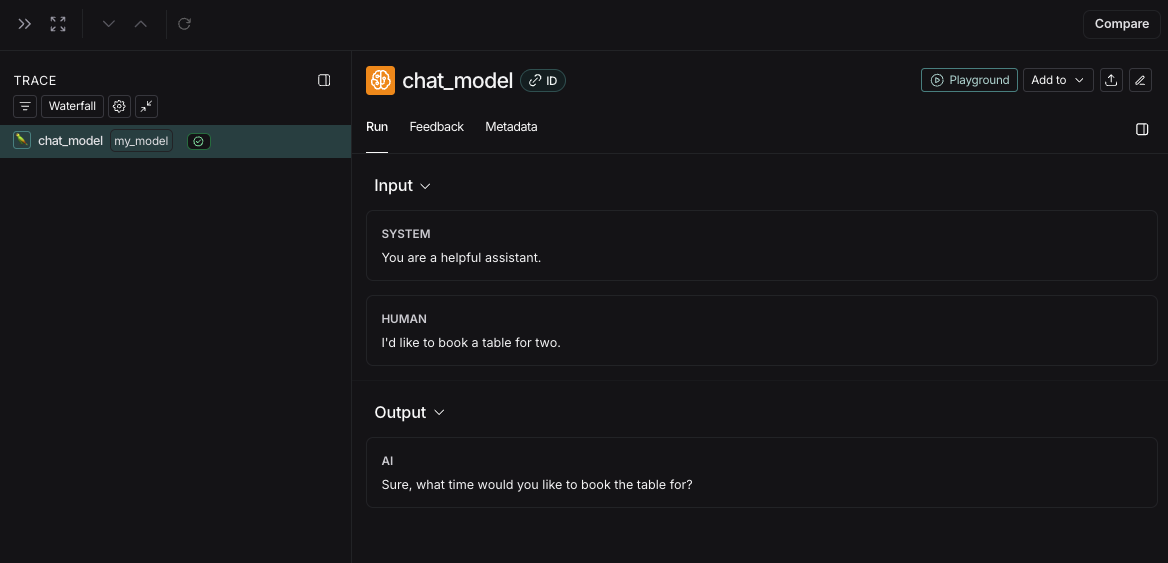
from langsmith import traceableinputs = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "I'd like to book a table for two."},]output = { "choices": [ { "message": { "role": "assistant", "content": "Sure, what time would you like to book the table for?" } } ]}@traceable( run_type="llm", metadata={"ls_provider": "my_provider", "ls_model_name": "my_model"})def chat_model(messages: list): return outputchat_model(inputs)
class UsageMetadata(TypedDict, total=False): input_tokens: int """The number of tokens used for the prompt.""" output_tokens: int """The number of tokens generated as output.""" total_tokens: int """The total number of tokens used.""" input_token_details: dict[str, float] """The details of the input tokens.""" output_token_details: dict[str, float] """The details of the output tokens.""" input_cost: float """The cost of the input tokens.""" output_cost: float """The cost of the output tokens.""" total_cost: float """The total cost of the tokens.""" input_cost_details: dict[str, float] """The cost details of the input tokens.""" output_cost_details: dict[str, float] """The cost details of the output tokens."""
from langsmith import traceable, get_current_run_treeinputs = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "I'd like to book a table for two."},]@traceable( run_type="llm", metadata={"ls_provider": "my_provider", "ls_model_name": "my_model"})def chat_model(messages: list): llm_output = { "choices": [ { "message": { "role": "assistant", "content": "Sure, what time would you like to book the table for?" } } ], "usage_metadata": { "input_tokens": 27, "output_tokens": 13, "total_tokens": 40, "input_token_details": {"cache_read": 10}, # If you wanted to specify costs: # "input_cost": 1.1e-6, # "input_cost_details": {"cache_read": 2.3e-7}, # "output_cost": 5.0e-6, }, } run = get_current_run_tree() run.set(usage_metadata=llm_output["usage_metadata"]) return llm_output["choices"][0]["message"]chat_model(inputs)
from langsmith import traceableinputs = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "I'd like to book a table for two."},]output = { "choices": [ { "message": { "role": "assistant", "content": "Sure, what time would you like to book the table for?" } } ], "usage_metadata": { "input_tokens": 27, "output_tokens": 13, "total_tokens": 40, "input_token_details": {"cache_read": 10}, # If you wanted to specify costs: # "input_cost": 1.1e-6, # "input_cost_details": {"cache_read": 2.3e-7}, # "output_cost": 5.0e-6, },}@traceable( run_type="llm", metadata={"ls_provider": "my_provider", "ls_model_name": "my_model"})def chat_model(messages: list): return outputchat_model(inputs)