

RAG 评估 | 评估器 | LLM 作为评判者的评估器
- 如何创建测试数据集
- 如何使用这些数据集运行您的 RAG 应用程序
- 如何使用不同的评估指标衡量应用程序的性能
概览
典型的 RAG 评估工作流程包含三个主要步骤- 创建包含问题及其预期答案的数据集
- 针对这些问题运行您的 RAG 应用程序
-
使用评估器来衡量应用程序的性能,考察以下因素:
- 答案相关性
- 答案准确性
- 检索质量
设置
环境
首先,让我们设置环境变量复制
向 AI 提问
import os
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = "YOUR LANGSMITH API KEY"
os.environ["OPENAI_API_KEY"] = "YOUR OPENAI API KEY"
复制
向 AI 提问
pip install -U langsmith langchain[openai] langchain-community
应用
虽然本教程使用 LangChain,但此处演示的评估技术和 LangSmith 功能适用于任何框架。您可以随意使用您喜欢的工具和库。
- 索引:将 Lilian Weng 的几篇博客文章分块并索引到向量存储中
- 检索:根据用户问题检索这些分块
- 生成:将问题和检索到的文档传递给 LLM。
索引和检索
首先,让我们加载我们要为其构建聊天机器人的博客文章并对其进行索引。复制
向 AI 提问
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# List of URLs to load documents from
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# Load documents from the URLs
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs_list)
# Add the document chunks to the "vector store" using OpenAIEmbeddings
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(),
)
# With langchain we can easily turn any vector store into a retrieval component:
retriever = vectorstore.as_retriever(k=6)
生成
我们现在可以定义生成管道。复制
向 AI 提问
from langchain_openai import ChatOpenAI
from langsmith import traceable
llm = ChatOpenAI(model="gpt-4o", temperature=1)
# Add decorator so this function is traced in LangSmith
@traceable()
def rag_bot(question: str) -> dict:
# LangChain retriever will be automatically traced
docs = retriever.invoke(question)
docs_string = "".join(doc.page_content for doc in docs)
instructions = f"""You are a helpful assistant who is good at analyzing source information and answering questions.
Use the following source documents to answer the user's questions.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Documents:
{docs_string}"""
# langchain ChatModel will be automatically traced
ai_msg = llm.invoke([
{"role": "system", "content": instructions},
{"role": "user", "content": question},
],
)
return {"answer": ai_msg.content, "documents": docs}
数据集
现在我们已经有了应用程序,让我们构建一个数据集来评估它。在这种情况下,我们的数据集将非常简单:我们将有示例问题和参考答案。复制
向 AI 提问
from langsmith import Client
client = Client()
# Define the examples for the dataset
examples = [
{
"inputs": {"question": "How does the ReAct agent use self-reflection? "},
"outputs": {"answer": "ReAct integrates reasoning and acting, performing actions - such tools like Wikipedia search API - and then observing / reasoning about the tool outputs."},
},
{
"inputs": {"question": "What are the types of biases that can arise with few-shot prompting?"},
"outputs": {"answer": "The biases that can arise with few-shot prompting include (1) Majority label bias, (2) Recency bias, and (3) Common token bias."},
},
{
"inputs": {"question": "What are five types of adversarial attacks?"},
"outputs": {"answer": "Five types of adversarial attacks are (1) Token manipulation, (2) Gradient based attack, (3) Jailbreak prompting, (4) Human red-teaming, (5) Model red-teaming."},
},
]
# Create the dataset and examples in LangSmith
dataset_name = "Lilian Weng Blogs Q&A"
dataset = client.create_dataset(dataset_name=dataset_name)
client.create_examples(
dataset_id=dataset.id,
examples=examples
)
评估器
思考不同类型的 RAG 评估器的一种方式是将其视为正在评估的内容 X 正在与什么进行评估的元组- 正确性:回复 vs 参考答案
目标:衡量“RAG 链答案与真实答案的相似/正确程度”模式:需要通过数据集提供真实(参考)答案评估器:使用 LLM 作为评判者来评估答案的正确性。
- 相关性:回复 vs 输入
目标:衡量“生成的回复在多大程度上解决了初始用户输入”模式:不需要参考答案,因为它会将答案与输入问题进行比较评估器:使用 LLM 作为评判者来评估答案的相关性、有用性等。
- 基础性:回复 vs 检索到的文档
目标:衡量“生成的回复在多大程度上与检索到的上下文一致”模式:不需要参考答案,因为它会将答案与检索到的上下文进行比较评估器:使用 LLM 作为评判者来评估忠实度、幻觉等。
- 检索相关性:检索到的文档 vs 输入
目标:衡量“我的检索结果与此查询的相关性如何”模式:不需要参考答案,因为它会将问题与检索到的上下文进行比较评估器:使用 LLM 作为评判者来评估相关性
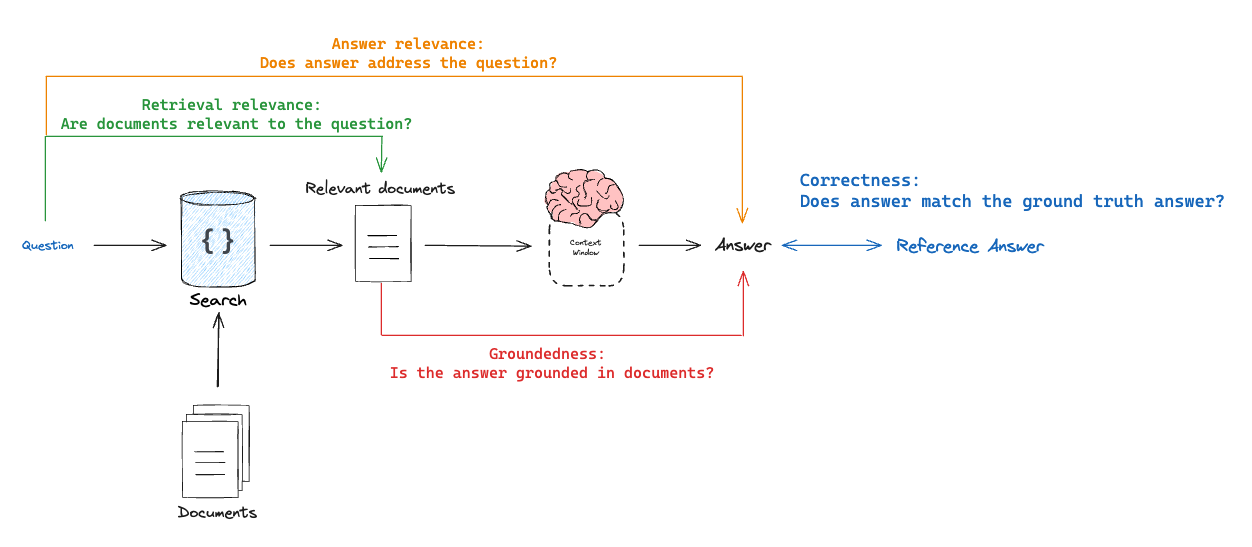
正确性:回复 vs 参考答案
复制
向 AI 提问
from typing_extensions import Annotated, TypedDict
# Grade output schema
class CorrectnessGrade(TypedDict):
# Note that the order in the fields are defined is the order in which the model will generate them.
# It is useful to put explanations before responses because it forces the model to think through
# its final response before generating it:
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
correct: Annotated[bool, ..., "True if the answer is correct, False otherwise."]
# Grade prompt
correctness_instructions = """You are a teacher grading a quiz. You will be given a QUESTION, the GROUND TRUTH (correct) ANSWER, and the STUDENT ANSWER. Here is the grade criteria to follow:
(1) Grade the student answers based ONLY on their factual accuracy relative to the ground truth answer. (2) Ensure that the student answer does not contain any conflicting statements.
(3) It is OK if the student answer contains more information than the ground truth answer, as long as it is factually accurate relative to the ground truth answer.
Correctness:
A correctness value of True means that the student's answer meets all of the criteria.
A correctness value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
grader_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
CorrectnessGrade, method="json_schema", strict=True
)
def correctness(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
"""An evaluator for RAG answer accuracy"""
answers = f"""\
QUESTION: {inputs['question']}
GROUND TRUTH ANSWER: {reference_outputs['answer']}
STUDENT ANSWER: {outputs['answer']}"""
# Run evaluator
grade = grader_llm.invoke([
{"role": "system", "content": correctness_instructions},
{"role": "user", "content": answers}
])
return grade["correct"]
相关性:回复 vs 输入
流程与上述类似,但我们只查看inputs 和 outputs,而不需要 reference_outputs。没有参考答案我们就无法评估准确性,但仍然可以评估相关性——即模型是否回答了用户的问题。
复制
向 AI 提问
# Grade output schema
class RelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
relevant: Annotated[
bool, ..., "Provide the score on whether the answer addresses the question"
]
# Grade prompt
relevance_instructions = """You are a teacher grading a quiz. You will be given a QUESTION and a STUDENT ANSWER. Here is the grade criteria to follow:
(1) Ensure the STUDENT ANSWER is concise and relevant to the QUESTION
(2) Ensure the STUDENT ANSWER helps to answer the QUESTION
Relevance:
A relevance value of True means that the student's answer meets all of the criteria.
A relevance value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
relevance_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
RelevanceGrade, method="json_schema", strict=True
)
# Evaluator
def relevance(inputs: dict, outputs: dict) -> bool:
"""A simple evaluator for RAG answer helpfulness."""
answer = f"QUESTION: {inputs['question']}\nSTUDENT ANSWER: {outputs['answer']}"
grade = relevance_llm.invoke([
{"role": "system", "content": relevance_instructions},
{"role": "user", "content": answer}
])
return grade["relevant"]
基础性:回复 vs 检索到的文档
另一种无需参考答案即可评估回复的有用方法是检查回复是否由检索到的文档证明(或“基于”)合理。复制
向 AI 提问
# Grade output schema
class GroundedGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
grounded: Annotated[
bool, ..., "Provide the score on if the answer hallucinates from the documents"
]
# Grade prompt
grounded_instructions = """You are a teacher grading a quiz. You will be given FACTS and a STUDENT ANSWER. Here is the grade criteria to follow:
(1) Ensure the STUDENT ANSWER is grounded in the FACTS. (2) Ensure the STUDENT ANSWER does not contain "hallucinated" information outside the scope of the FACTS.
Grounded:
A grounded value of True means that the student's answer meets all of the criteria.
A grounded value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
grounded_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
GroundedGrade, method="json_schema", strict=True
)
# Evaluator
def groundedness(inputs: dict, outputs: dict) -> bool:
"""A simple evaluator for RAG answer groundedness."""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"FACTS: {doc_string}\nSTUDENT ANSWER: {outputs['answer']}"
grade = grounded_llm.invoke([
{"role": "system", "content": grounded_instructions},
{"role": "user", "content": answer}
])
return grade["grounded"]
检索相关性:检索到的文档 vs 输入
复制
向 AI 提问
# Grade output schema
class RetrievalRelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
relevant: Annotated[
bool,
...,
"True if the retrieved documents are relevant to the question, False otherwise",
]
# Grade prompt
retrieval_relevance_instructions = """You are a teacher grading a quiz. You will be given a QUESTION and a set of FACTS provided by the student. Here is the grade criteria to follow:
(1) You goal is to identify FACTS that are completely unrelated to the QUESTION
(2) If the facts contain ANY keywords or semantic meaning related to the question, consider them relevant
(3) It is OK if the facts have SOME information that is unrelated to the question as long as (2) is met
Relevance:
A relevance value of True means that the FACTS contain ANY keywords or semantic meaning related to the QUESTION and are therefore relevant.
A relevance value of False means that the FACTS are completely unrelated to the QUESTION.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
retrieval_relevance_llm = ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(RetrievalRelevanceGrade, method="json_schema", strict=True)
def retrieval_relevance(inputs: dict, outputs: dict) -> bool:
"""An evaluator for document relevance"""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"FACTS: {doc_string}\nQUESTION: {inputs['question']}"
# Run evaluator
grade = retrieval_relevance_llm.invoke([
{"role": "system", "content": retrieval_relevance_instructions},
{"role": "user", "content": answer}
])
return grade["relevant"]
运行评估
我们现在可以使用所有不同的评估器启动我们的评估作业。复制
向 AI 提问
def target(inputs: dict) -> dict:
return rag_bot(inputs["question"])
experiment_results = client.evaluate(
target,
data=dataset_name,
evaluators=[correctness, groundedness, relevance, retrieval_relevance],
experiment_prefix="rag-doc-relevance",
metadata={"version": "LCEL context, gpt-4-0125-preview"},
)
# Explore results locally as a dataframe if you have pandas installed
# experiment_results.to_pandas()
参考代码
这是一个包含上述所有代码的合并脚本
这是一个包含上述所有代码的合并脚本
复制
向 AI 提问
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langsmith import Client, traceable
from typing_extensions import Annotated, TypedDict
# List of URLs to load documents from
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# Load documents from the URLs
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs_list)
# Add the document chunks to the "vector store" using OpenAIEmbeddings
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(),
)
# With langchain we can easily turn any vector store into a retrieval component:
retriever = vectorstore.as_retriever(k=6)
llm = ChatOpenAI(model="gpt-4o", temperature=1)
# Add decorator so this function is traced in LangSmith
@traceable()
def rag_bot(question: str) -> dict:
# langchain Retriever will be automatically traced
docs = retriever.invoke(question)
docs_string = "".join(doc.page_content for doc in docs)
instructions = f"""You are a helpful assistant who is good at analyzing source information and answering questions.
Use the following source documents to answer the user's questions.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Documents:
{docs_string}"""
# langchain ChatModel will be automatically traced
ai_msg = llm.invoke([
{"role": "system", "content": instructions},
{"role": "user", "content": question},
],
)
return {"answer": ai_msg.content, "documents": docs}
client = Client()
# Define the examples for the dataset
examples = [
{
"inputs": {"question": "How does the ReAct agent use self-reflection? "},
"outputs": {"answer": "ReAct integrates reasoning and acting, performing actions - such tools like Wikipedia search API - and then observing / reasoning about the tool outputs."},
},
{
"inputs": {"question": "What are the types of biases that can arise with few-shot prompting?"},
"outputs": {"answer": "The biases that can arise with few-shot prompting include (1) Majority label bias, (2) Recency bias, and (3) Common token bias."},
},
{
"inputs": {"question": "What are five types of adversarial attacks?"},
"outputs": {"answer": "Five types of adversarial attacks are (1) Token manipulation, (2) Gradient based attack, (3) Jailbreak prompting, (4) Human red-teaming, (5) Model red-teaming."},
},
]
# Create the dataset and examples in LangSmith
dataset_name = "Lilian Weng Blogs Q&A"
if not client.has_dataset(dataset_name=dataset_name):
dataset = client.create_dataset(dataset_name=dataset_name)
client.create_examples(
dataset_id=dataset.id,
examples=examples
)
# Grade output schema
class CorrectnessGrade(TypedDict):
# Note that the order in the fields are defined is the order in which the model will generate them.
# It is useful to put explanations before responses because it forces the model to think through
# its final response before generating it:
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
correct: Annotated[bool, ..., "True if the answer is correct, False otherwise."]
# Grade prompt
correctness_instructions = """You are a teacher grading a quiz. You will be given a QUESTION, the GROUND TRUTH (correct) ANSWER, and the STUDENT ANSWER. Here is the grade criteria to follow:
(1) Grade the student answers based ONLY on their factual accuracy relative to the ground truth answer. (2) Ensure that the student answer does not contain any conflicting statements.
(3) It is OK if the student answer contains more information than the ground truth answer, as long as it is factually accurate relative to the ground truth answer.
Correctness:
A correctness value of True means that the student's answer meets all of the criteria.
A correctness value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
grader_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
CorrectnessGrade, method="json_schema", strict=True
)
def correctness(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
"""An evaluator for RAG answer accuracy"""
answers = f"""\
QUESTION: {inputs['question']}
GROUND TRUTH ANSWER: {reference_outputs['answer']}
STUDENT ANSWER: {outputs['answer']}"""
# Run evaluator
grade = grader_llm.invoke([
{"role": "system", "content": correctness_instructions},
{"role": "user", "content": answers},
]
)
return grade["correct"]
# Grade output schema
class RelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
relevant: Annotated[
bool, ..., "Provide the score on whether the answer addresses the question"
]
# Grade prompt
relevance_instructions = """You are a teacher grading a quiz. You will be given a QUESTION and a STUDENT ANSWER. Here is the grade criteria to follow:
(1) Ensure the STUDENT ANSWER is concise and relevant to the QUESTION
(2) Ensure the STUDENT ANSWER helps to answer the QUESTION
Relevance:
A relevance value of True means that the student's answer meets all of the criteria.
A relevance value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
relevance_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
RelevanceGrade, method="json_schema", strict=True
)
# Evaluator
def relevance(inputs: dict, outputs: dict) -> bool:
"""A simple evaluator for RAG answer helpfulness."""
answer = f"QUESTION: {inputs['question']}\nSTUDENT ANSWER: {outputs['answer']}"
grade = relevance_llm.invoke([
{"role": "system", "content": relevance_instructions},
{"role": "user", "content": answer},
]
)
return grade["relevant"]
# Grade output schema
class GroundedGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
grounded: Annotated[
bool, ..., "Provide the score on if the answer hallucinates from the documents"
]
# Grade prompt
grounded_instructions = """You are a teacher grading a quiz. You will be given FACTS and a STUDENT ANSWER. Here is the grade criteria to follow:
(1) Ensure the STUDENT ANSWER is grounded in the FACTS. (2) Ensure the STUDENT ANSWER does not contain "hallucinated" information outside the scope of the FACTS.
Grounded:
A grounded value of True means that the student's answer meets all of the criteria.
A grounded value of False means that the student's answer does not meet all of the criteria.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
grounded_llm = ChatOpenAI(model="gpt-4o", temperature=0).with_structured_output(
GroundedGrade, method="json_schema", strict=True
)
# Evaluator
def groundedness(inputs: dict, outputs: dict) -> bool:
"""A simple evaluator for RAG answer groundedness."""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"FACTS: {doc_string}\nSTUDENT ANSWER: {outputs['answer']}"
grade = grounded_llm.invoke([
{"role": "system", "content": grounded_instructions},
{"role": "user", "content": answer},
]
)
return grade["grounded"]
# Grade output schema
class RetrievalRelevanceGrade(TypedDict):
explanation: Annotated[str, ..., "Explain your reasoning for the score"]
relevant: Annotated[
bool,
...,
"True if the retrieved documents are relevant to the question, False otherwise",
]
# Grade prompt
retrieval_relevance_instructions = """You are a teacher grading a quiz. You will be given a QUESTION and a set of FACTS provided by the student. Here is the grade criteria to follow:
(1) You goal is to identify FACTS that are completely unrelated to the QUESTION
(2) If the facts contain ANY keywords or semantic meaning related to the question, consider them relevant
(3) It is OK if the facts have SOME information that is unrelated to the question as long as (2) is met
Relevance:
A relevance value of True means that the FACTS contain ANY keywords or semantic meaning related to the QUESTION and are therefore relevant.
A relevance value of False means that the FACTS are completely unrelated to the QUESTION.
Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct. Avoid simply stating the correct answer at the outset."""
# Grader LLM
retrieval_relevance_llm = ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(RetrievalRelevanceGrade, method="json_schema", strict=True)
def retrieval_relevance(inputs: dict, outputs: dict) -> bool:
"""An evaluator for document relevance"""
doc_string = "\n\n".join(doc.page_content for doc in outputs["documents"])
answer = f"FACTS: {doc_string}\nQUESTION: {inputs['question']}"
# Run evaluator
grade = retrieval_relevance_llm.invoke([
{"role": "system", "content": retrieval_relevance_instructions},
{"role": "user", "content": answer},
]
)
return grade["relevant"]
def target(inputs: dict) -> dict:
return rag_bot(inputs["question"])
experiment_results = client.evaluate(
target,
data=dataset_name,
evaluators=[correctness, groundedness, relevance, retrieval_relevance],
experiment_prefix="rag-doc-relevance",
metadata={"version": "LCEL context, gpt-4-0125-preview"},
)
# Explore results locally as a dataframe if you have pandas installed
# experiment_results.to_pandas()
以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。