import openai
from langsmith import Client, wrappers
# Application code
openai_client = wrappers.wrap_openai(openai.OpenAI())
default_instructions = "Respond to the users question in a short, concise manner (one short sentence)."
def my_app(question: str, model: str = "gpt-4o-mini", instructions: str = default_instructions) -> str:
return openai_client.chat.completions.create(
model=model,
temperature=0,
messages=[
{"role": "system", "content": instructions},
{"role": "user", "content": question},
],
).choices[0].message.content
client = Client()
# Define dataset: these are your test cases
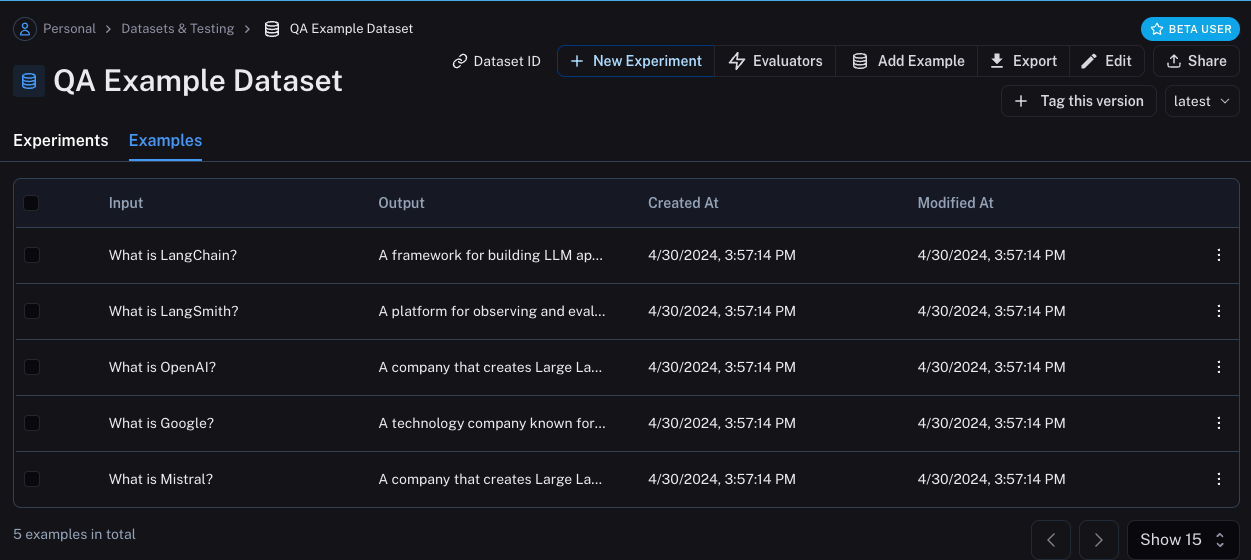
dataset_name = "QA Example Dataset"
dataset = client.create_dataset(dataset_name)
client.create_examples(
dataset_id=dataset.id,
examples=[
{
"inputs": {"question": "What is LangChain?"},
"outputs": {"answer": "A framework for building LLM applications"},
},
{
"inputs": {"question": "What is LangSmith?"},
"outputs": {"answer": "A platform for observing and evaluating LLM applications"},
},
{
"inputs": {"question": "What is OpenAI?"},
"outputs": {"answer": "A company that creates Large Language Models"},
},
{
"inputs": {"question": "What is Google?"},
"outputs": {"answer": "A technology company known for search"},
},
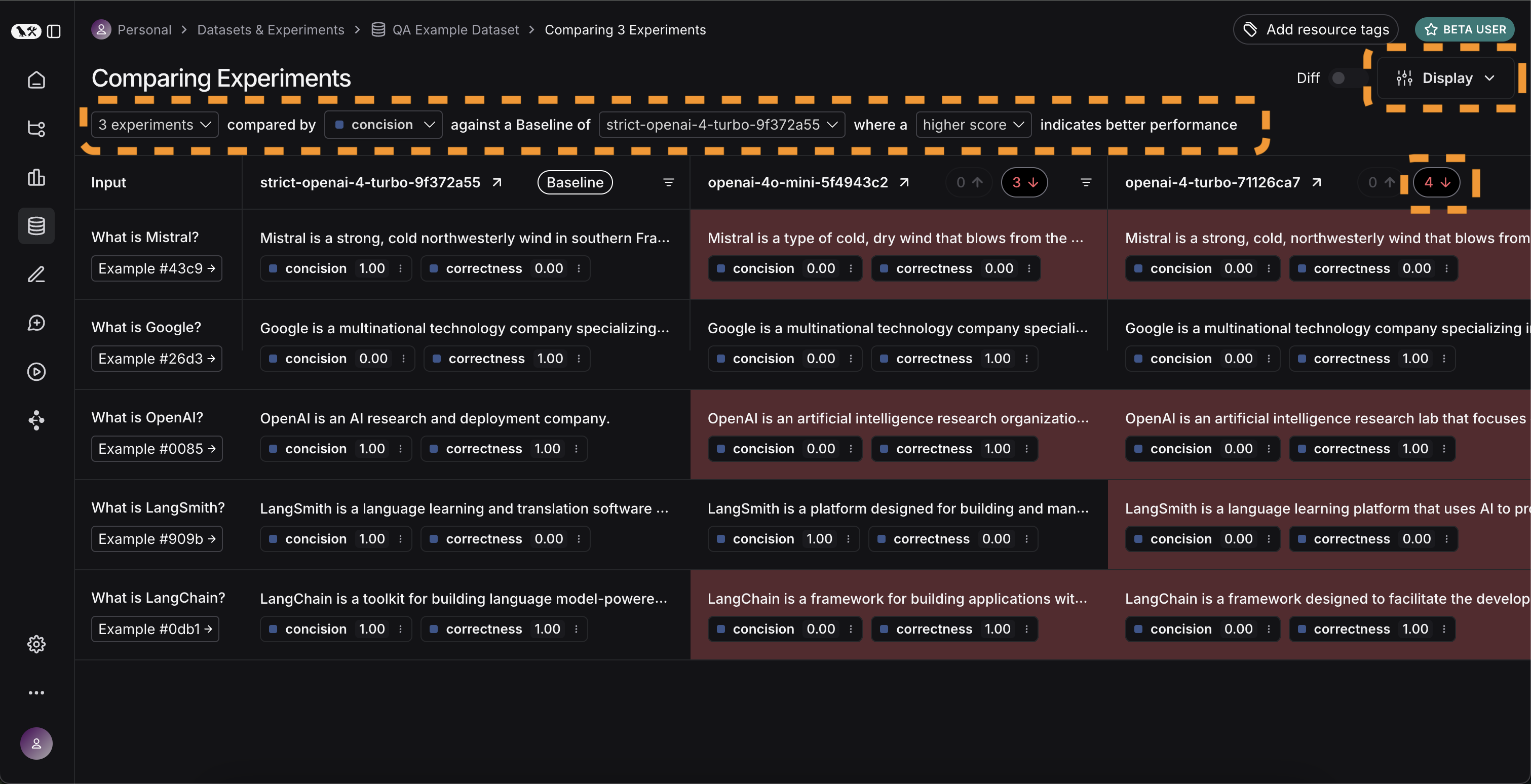
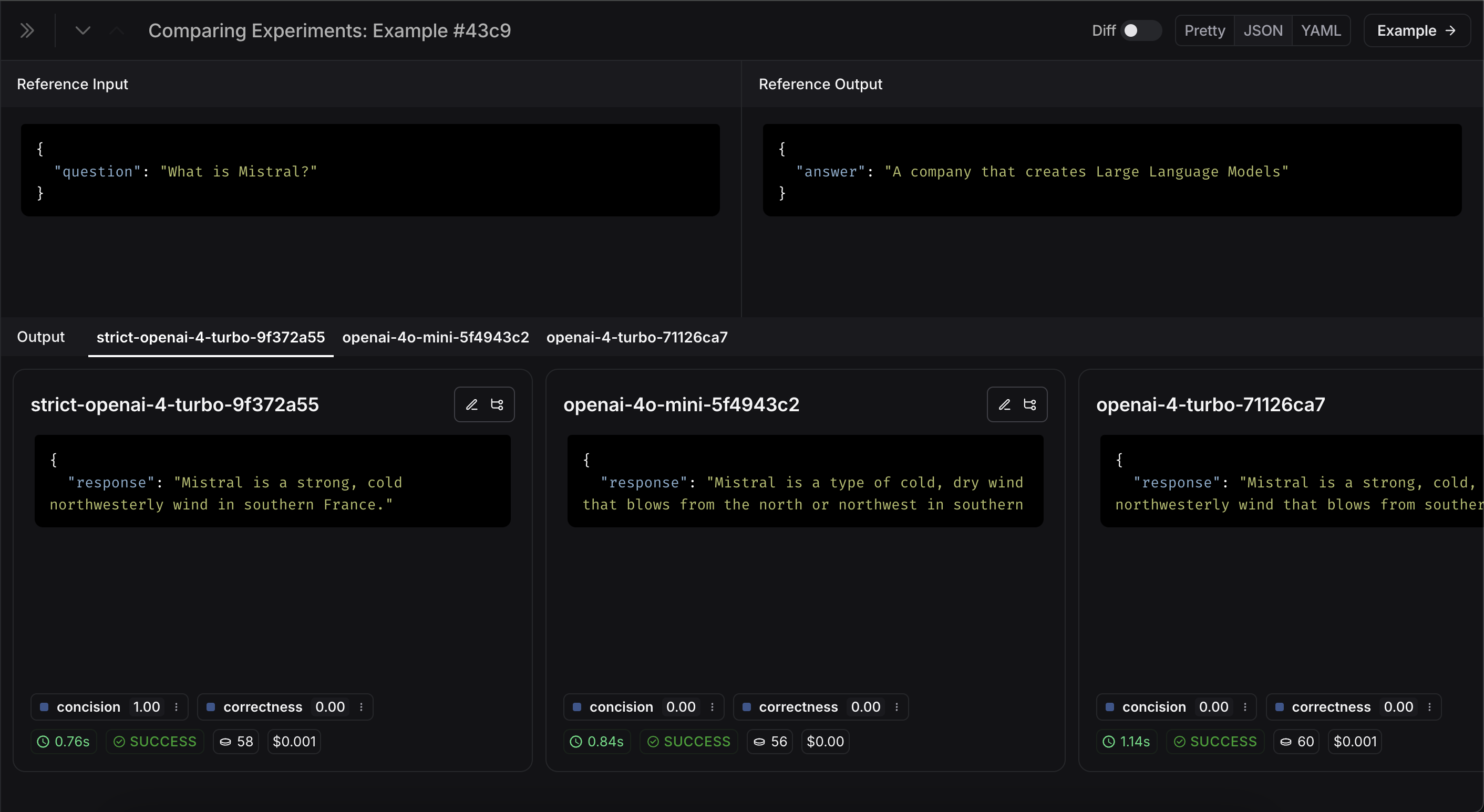
{
"inputs": {"question": "What is Mistral?"},
"outputs": {"answer": "A company that creates Large Language Models"},
}
]
)
# Define evaluators
eval_instructions = "You are an expert professor specialized in grading students' answers to questions."
def correctness(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
user_content = f"""You are grading the following question:
{inputs['question']}
Here is the real answer:
{reference_outputs['answer']}
You are grading the following predicted answer:
{outputs['response']}
Respond with CORRECT or INCORRECT:
Grade:"""
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
temperature=0,
messages=[
{"role": "system", "content": eval_instructions},
{"role": "user", "content": user_content},
],
).choices[0].message.content
return response == "CORRECT"
def concision(outputs: dict, reference_outputs: dict) -> bool:
return int(len(outputs["response"]) < 2 * len(reference_outputs["answer"]))
# Run evaluations
def ls_target(inputs: str) -> dict:
return {"response": my_app(inputs["question"])}
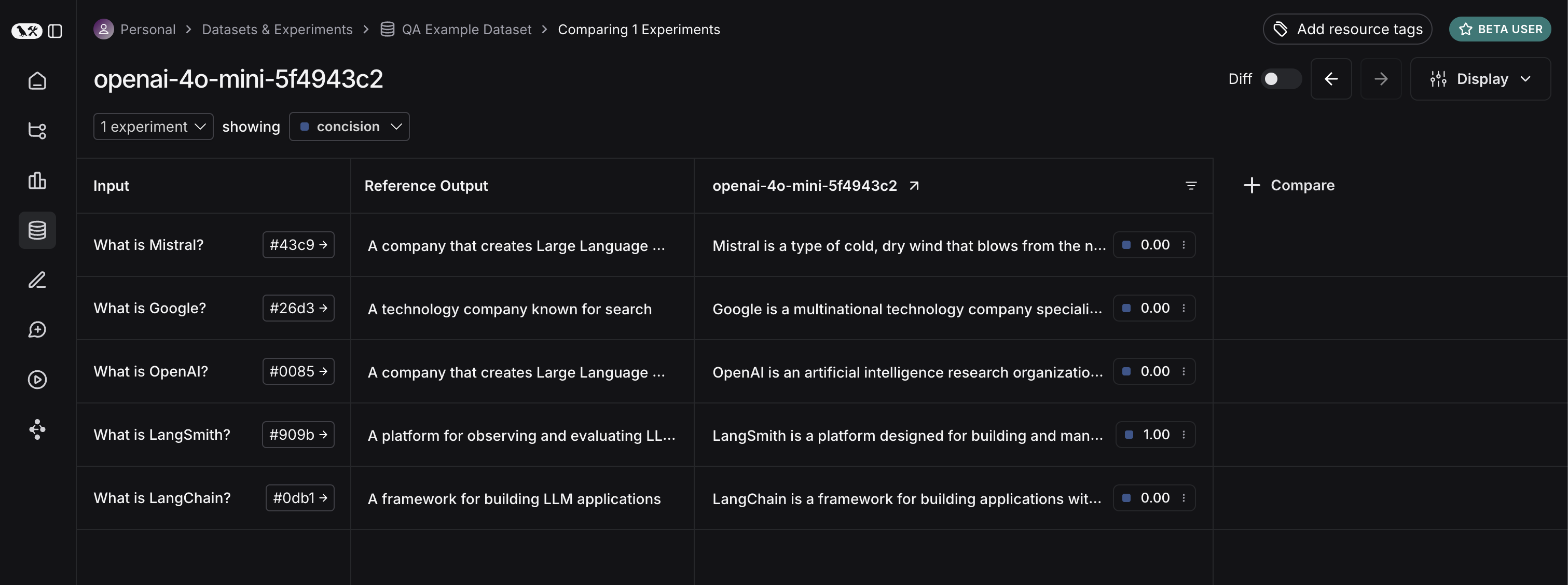
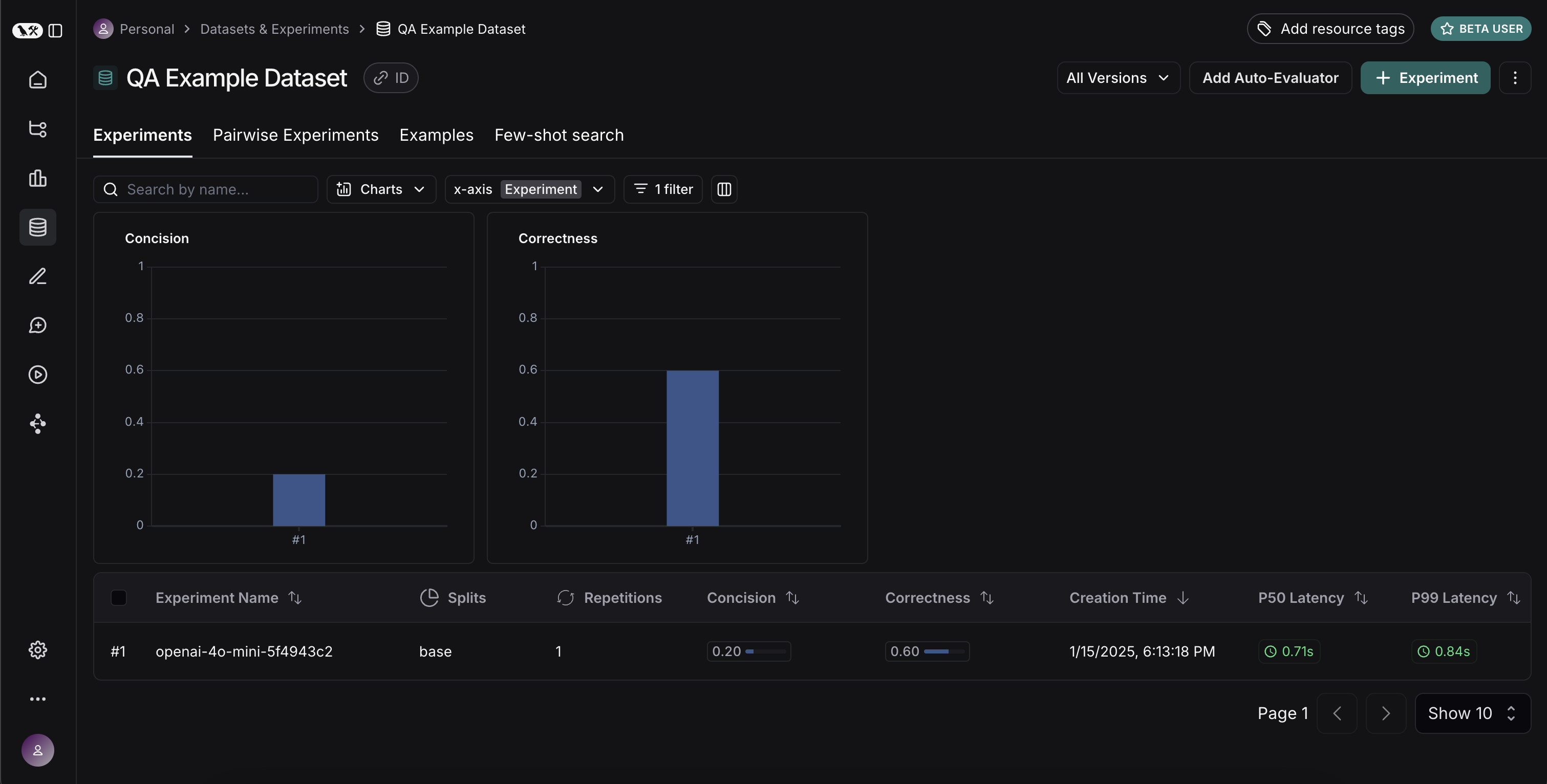
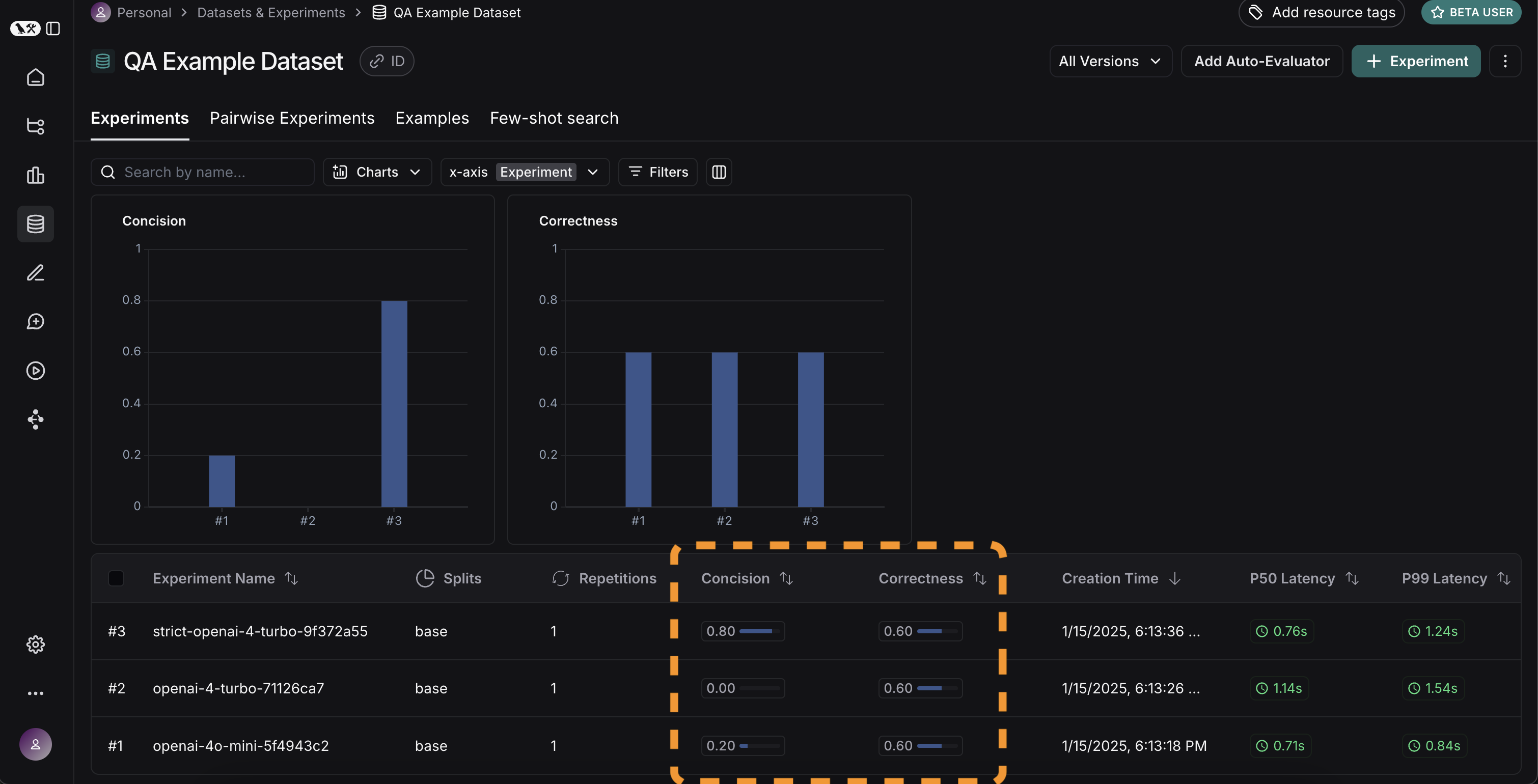
experiment_results_v1 = client.evaluate(
ls_target, # Your AI system
data=dataset_name, # The data to predict and grade over
evaluators=[concision, correctness], # The evaluators to score the results
experiment_prefix="openai-4o-mini", # A prefix for your experiment names to easily identify them
)
def ls_target_v2(inputs: str) -> dict:
return {"response": my_app(inputs["question"], model="gpt-4-turbo")}
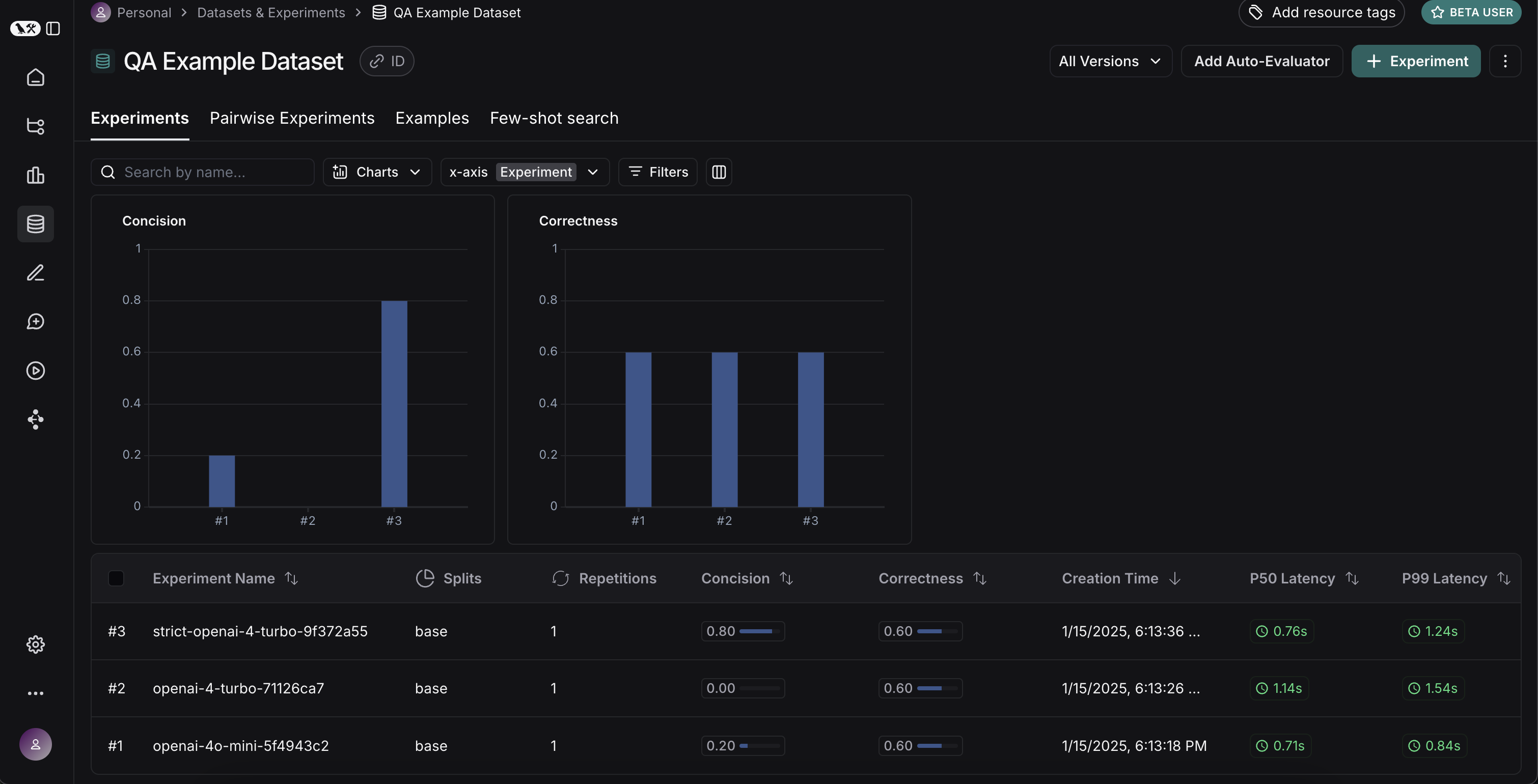
experiment_results_v2 = client.evaluate(
ls_target_v2,
data=dataset_name,
evaluators=[concision, correctness],
experiment_prefix="openai-4-turbo",
)
instructions_v3 = "Respond to the users question in a short, concise manner (one short sentence). Do NOT use more than ten words."
def ls_target_v3(inputs: str) -> dict:
response = my_app(
inputs["question"],
model="gpt-4-turbo",
instructions=instructions_v3
)
return {"response": response}
experiment_results_v3 = client.evaluate(
ls_target_v3,
data=dataset_name,
evaluators=[concision, correctness],
experiment_prefix="strict-openai-4-turbo",
)