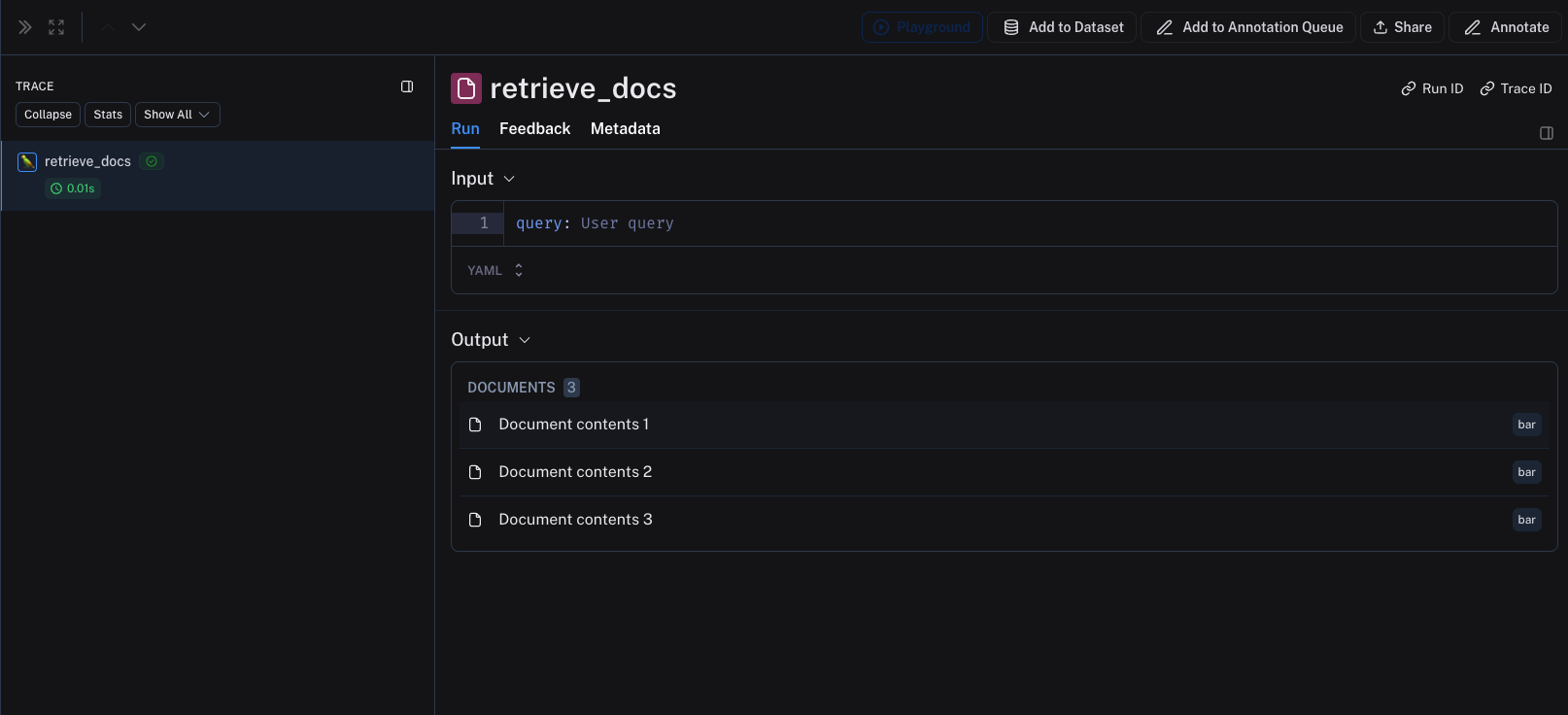
即使您未以正确的格式记录检索器追踪,也并不会导致任何错误,数据仍将被记录。然而,数据将不会以检索器步骤特有的方式呈现。
-
使用
run_type="retriever" 注释检索步骤。
-
从检索器步骤返回 Python 字典或 TypeScript 对象的列表。每个字典都应包含以下键:
page_content:文档的文本内容。type:应始终为“Document”。metadata:一个 Python 字典或 TypeScript 对象,包含有关文档的元数据。此元数据将显示在追踪中。
以下代码片段展示了如何在 Python 和 TypeScript 中记录检索步骤。
from langsmith import traceable
def _convert_docs(results):
return [
{
"page_content": r,
"type": "Document",
"metadata": {"foo": "bar"}
}
for r in results
]
@traceable(run_type="retriever")
def retrieve_docs(query):
# Foo retriever returning hardcoded dummy documents.
# In production, this could be a real vector datatabase or other document index.
contents = ["Document contents 1", "Document contents 2", "Document contents 3"]
return _convert_docs(contents)
retrieve_docs("User query")