

- 评估检索步骤,以确保根据输入查询检索到正确的文档。
- 评估生成步骤,以确保根据检索到的文档生成正确的答案。
1. 定义你的 LLM 管道
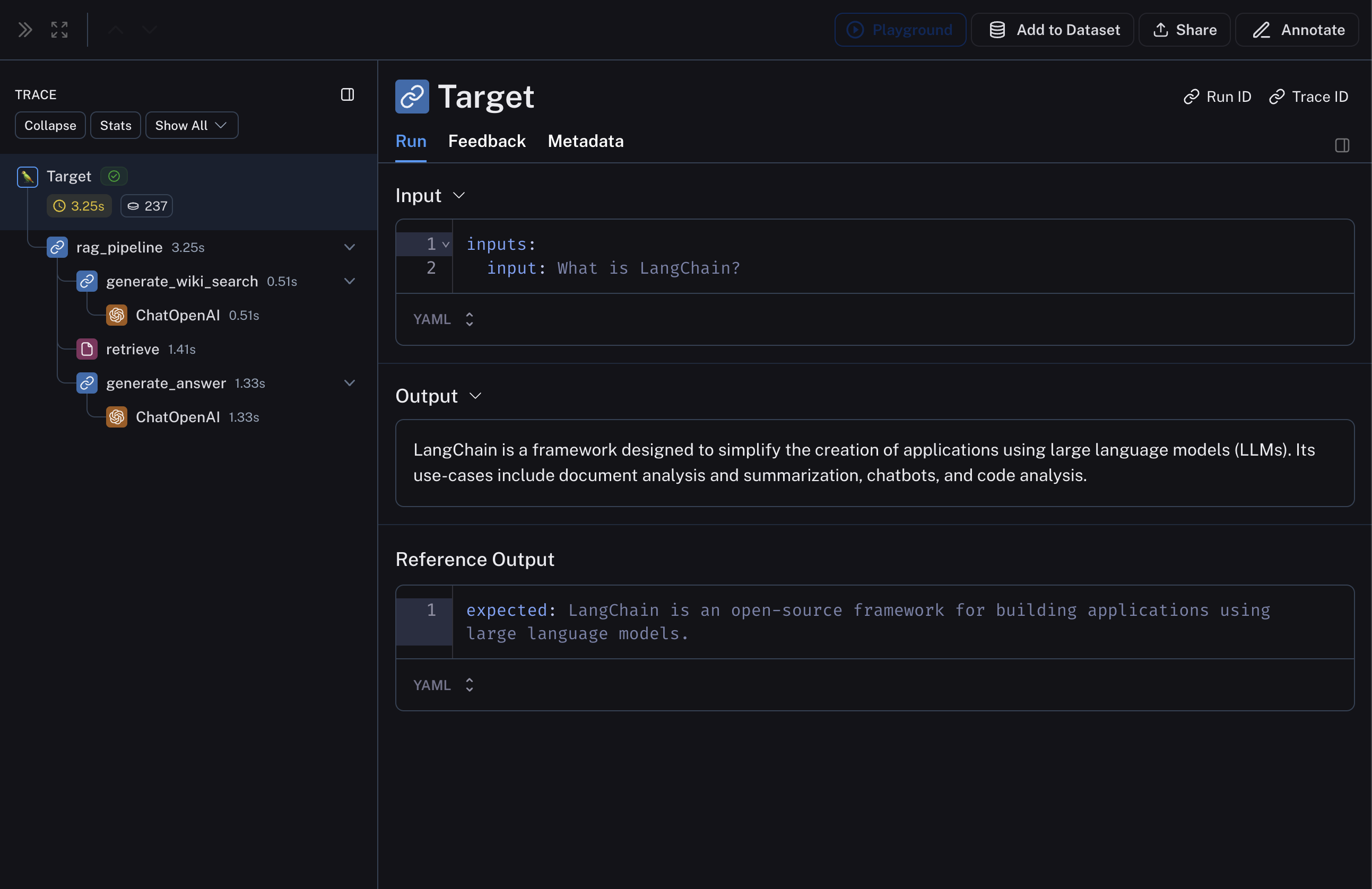
下面的 RAG 管道包括 1) 根据输入问题生成维基百科查询,2) 从维基百科检索相关文档,以及 3) 根据检索到的文档生成答案。复制
向 AI 提问
pip install -U langsmith langchain[openai] wikipedia
langsmith>=0.3.13
复制
向 AI 提问
import wikipedia as wp
from openai import OpenAI
from langsmith import traceable, wrappers
oai_client = wrappers.wrap_openai(OpenAI())
@traceable
def generate_wiki_search(question: str) -> str:
"""Generate the query to search in wikipedia."""
instructions = (
"Generate a search query to pass into wikipedia to answer the user's question. "
"Return only the search query and nothing more. "
"This will passed in directly to the wikipedia search engine."
)
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": question}
]
result = oai_client.chat.completions.create(
messages=messages,
model="gpt-4o-mini",
temperature=0,
)
return result.choices[0].message.content
@traceable(run_type="retriever")
def retrieve(query: str) -> list:
"""Get up to two search wikipedia results."""
results = []
for term in wp.search(query, results = 10):
try:
page = wp.page(term, auto_suggest=False)
results.append({
"page_content": page.summary,
"type": "Document",
"metadata": {"url": page.url}
})
except wp.DisambiguationError:
pass
if len(results) >= 2:
return results
@traceable
def generate_answer(question: str, context: str) -> str:
"""Answer the question based on the retrieved information."""
instructions = f"Answer the user's question based ONLY on the content below:\n\n{context}"
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": question}
]
result = oai_client.chat.completions.create(
messages=messages,
model="gpt-4o-mini",
temperature=0
)
return result.choices[0].message.content
@traceable
def qa_pipeline(question: str) -> str:
"""The full pipeline."""
query = generate_wiki_search(question)
context = "\n\n".join([doc["page_content"] for doc in retrieve(query)])
return generate_answer(question, context)
2. 创建一个数据集和示例来评估管道
我们正在构建一个非常简单的数据集,其中包含几个示例来评估管道。 需要 `langsmith>=0.3.13`复制
向 AI 提问
from langsmith import Client
ls_client = Client()
dataset_name = "Wikipedia RAG"
if not ls_client.has_dataset(dataset_name=dataset_name):
dataset = ls_client.create_dataset(dataset_name=dataset_name)
examples = [
{"inputs": {"question": "What is LangChain?"}},
{"inputs": {"question": "What is LangSmith?"}},
]
ls_client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
3. 定义你的自定义评估器
如上所述,我们将定义两个评估器:一个评估检索到的文档与输入查询的相关性,另一个评估生成答案与检索到的文档的幻觉。我们将使用 LangChain LLM 包装器,结合 `with_structured_output` 来定义幻觉评估器。 这里的关键是评估器函数应该遍历 `run` / `rootRun` 参数以访问管道的中间步骤。评估器随后可以处理中间步骤的输入和输出,以便根据所需的标准进行评估。 示例为方便起见使用 `langchain`,这不是必需的。复制
向 AI 提问
from langchain.chat_models import init_chat_model
from langsmith.schemas import Run
from pydantic import BaseModel, Field
def document_relevance(run: Run) -> bool:
"""Checks if retriever input exists in the retrieved docs."""
qa_pipeline_run = next(
r for run in run.child_runs if r.name == "qa_pipeline"
)
retrieve_run = next(
r for run in qa_pipeline_run.child_runs if r.name == "retrieve"
)
page_contents = "\n\n".join(
doc["page_content"] for doc in retrieve_run.outputs["output"]
)
return retrieve_run.inputs["query"] in page_contents
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
is_grounded: bool = Field(..., description="True if the answer is grounded in the facts, False otherwise.")
# LLM with structured outputs for grading hallucinations
# For more see: https://python.langchain.ac.cn/docs/how_to/structured_output/
grader_llm= init_chat_model("gpt-4o-mini", temperature=0).with_structured_output(
GradeHallucinations,
method="json_schema",
strict=True,
)
def no_hallucination(run: Run) -> bool:
"""Check if the answer is grounded in the documents.
Return True if there is no hallucination, False otherwise.
"""
# Get documents and answer
qa_pipeline_run = next(
r for r in run.child_runs if r.name == "qa_pipeline"
)
retrieve_run = next(
r for r in qa_pipeline_run.child_runs if r.name == "retrieve"
)
retrieved_content = "\n\n".join(
doc["page_content"] for doc in retrieve_run.outputs["output"]
)
# Construct prompt
instructions = (
"You are a grader assessing whether an LLM generation is grounded in / "
"supported by a set of retrieved facts. Give a binary score 1 or 0, "
"where 1 means that the answer is grounded in / supported by the set of facts."
)
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": f"Set of facts:\n{retrieved_content}\n\nLLM generation: {run.outputs['answer']}"},
]
grade = grader_llm.invoke(messages)
return grade.is_grounded
4. 评估管道
最后,我们将使用上面定义的自定义评估器运行 `evaluate`。复制
向 AI 提问
def qa_wrapper(inputs: dict) -> dict:
"""Wrap the qa_pipeline so it can accept the Example.inputs dict as input."""
return {"answer": qa_pipeline(inputs["question"])}
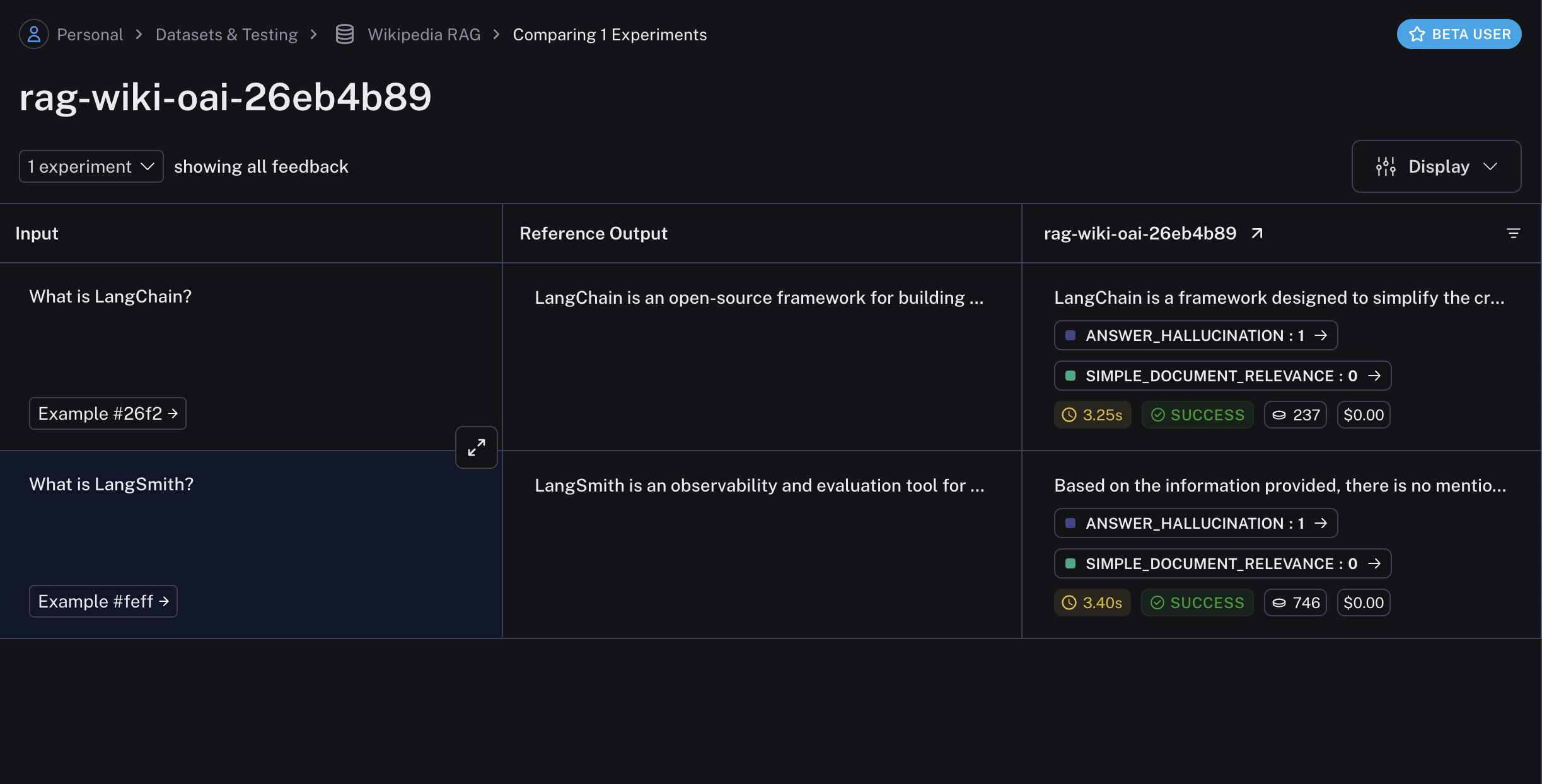
experiment_results = ls_client.evaluate(
qa_wrapper,
data=dataset_name,
evaluators=[document_relevance, no_hallucination],
experiment_prefix="rag-wiki-oai"
)
相关
以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。