

- 与对现有轨迹的完整数据集进行评估相比,入门更容易
- 从初始查询到成功或不成功的解决的端到端覆盖
- 能够检测应用程序多次迭代中的重复行为或上下文丢失
openevals 软件包模拟多轮交互并进行评估,该软件包包含预构建的评估器和其他方便的资源,用于评估您的 AI 应用程序。它还将使用 OpenAI 模型,尽管您也可以使用其他提供商。设置
首先,确保您已安装所需的依赖项如果您使用
yarn 作为包管理器,您还需要手动安装 @langchain/core 作为 openevals 的对等依赖项。对于一般的 LangSmith 评估,这不是必需的。运行模拟
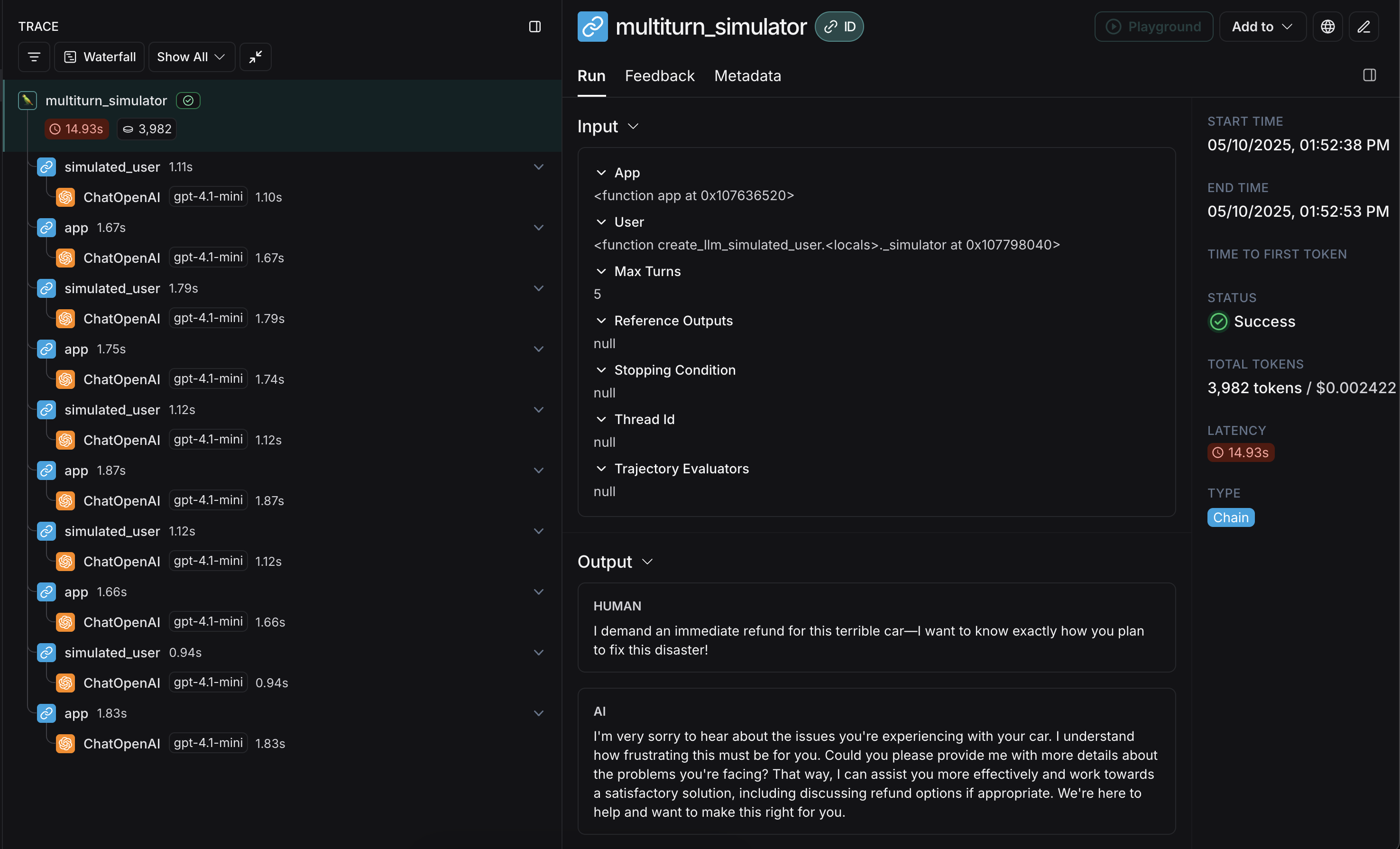
您需要两个主要组件才能开始使用app:您的应用程序,或包装它的函数。必须接受单个聊天消息(带有“role”和“content”键的字典)作为输入参数,并接受thread_id作为关键字参数。应接受其他关键字参数,因为未来版本可能会添加更多。返回一个至少包含 role 和 content 键的聊天消息作为输出。user:模拟用户。在本指南中,我们将使用一个导入的预构建函数create_llm_simulated_user,它使用 LLM 生成用户响应,不过您也可以创建自己的。
openevals 中的模拟器会在每次轮次中将单个聊天消息从 user 传递给您的 app。因此,如有需要,您应根据 thread_id 在内部有状态地跟踪当前历史记录。 以下是一个模拟多轮客户支持交互的示例。本指南使用一个简单的聊天应用程序,该应用程序封装了对 OpenAI 聊天补全 API 的单个调用,但这正是您调用应用程序或代理的地方。在此示例中,我们的模拟用户扮演了一个特别咄咄逼人的客户的角色:user 生成初始查询,然后来回传递响应聊天消息,直到达到 max_turns(您可以选择传递一个 stopping_condition,它接受当前轨迹并返回 True 或 False - 有关更多信息,请参阅 OpenEvals README)。返回值是构成对话轨迹的最终聊天消息列表。
有几种方法可以配置模拟用户,例如让它在前几轮模拟中返回固定响应,以及整个模拟。有关详细信息,请查看OpenEvals README。
app 和 user 的响应交错出现: 在 LangSmith 实验中运行
您可以将多轮模拟的结果作为 LangSmith 实验的一部分,以跟踪性能和随时间的变化。对于这些部分,熟悉 LangSmith 的pytest(仅限 Python)、Vitest/Jest(仅限 JS)或 evaluate 运行器之一会有所帮助。
使用 pytest 或 Vitest/Jest
请参阅以下指南,了解如何使用 LangSmith 与测试框架的集成来设置评估
trajectory_evaluators 参数传入。这些评估器将在模拟结束时运行,将最终的聊天消息列表作为 outputs 关键字参数。因此,您传入的 trajectory_evaluator 必须接受此关键字参数。 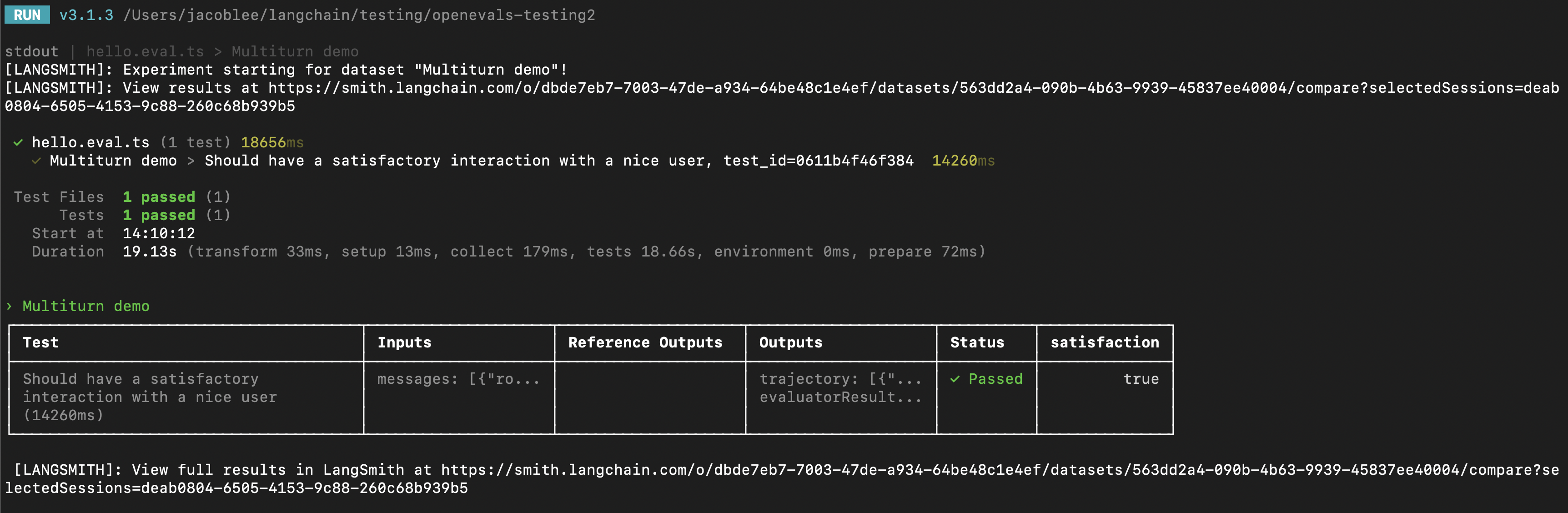
trajectory_evaluators 返回的反馈,并将其添加到实验中。另请注意,测试用例使用模拟用户上的 fixed_responses 参数来以特定输入开始对话,您可以记录并使其成为存储数据集的一部分。 您可能还会发现将模拟用户的系统提示也作为记录数据集的一部分很方便。使用 evaluate
您还可以使用 evaluate 运行器来评估模拟的多轮交互。这与 pytest/Vitest/Jest 示例在以下方面有所不同
- 模拟应作为您的
target函数的一部分,并且您的 target 函数应返回最终的轨迹。- 这将使轨迹成为 LangSmith 传递给您的评估器的
outputs。
- 这将使轨迹成为 LangSmith 传递给您的评估器的
- 您应该将评估器作为参数传递给
evaluate()方法,而不是使用trajectory_evaluators参数。 - 您将需要一个包含输入和(可选)参考轨迹的现有数据集。
修改模拟用户角色
上述示例使用所有输入示例的相同模拟用户角色运行,该角色由传递给create_llm_simulated_user 的 system 参数定义。如果您想为数据集中的特定项使用不同的角色,您可以更新数据集示例,使其还包含一个带有所需 system 提示的额外字段,然后在创建模拟用户时传入该字段,如下所示
后续步骤
您刚刚了解了一些模拟多轮交互并在 LangSmith 评估中运行它们的技术。 以下是您可能希望接下来探索的一些主题: 您还可以探索 OpenEvals readme 以获取有关预构建评估器的更多信息。以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。