

- 由于更高效的二进制文件传输,上传和下载速度更快
- LangSmith UI 中不同文件类型的增强可视化
SDK
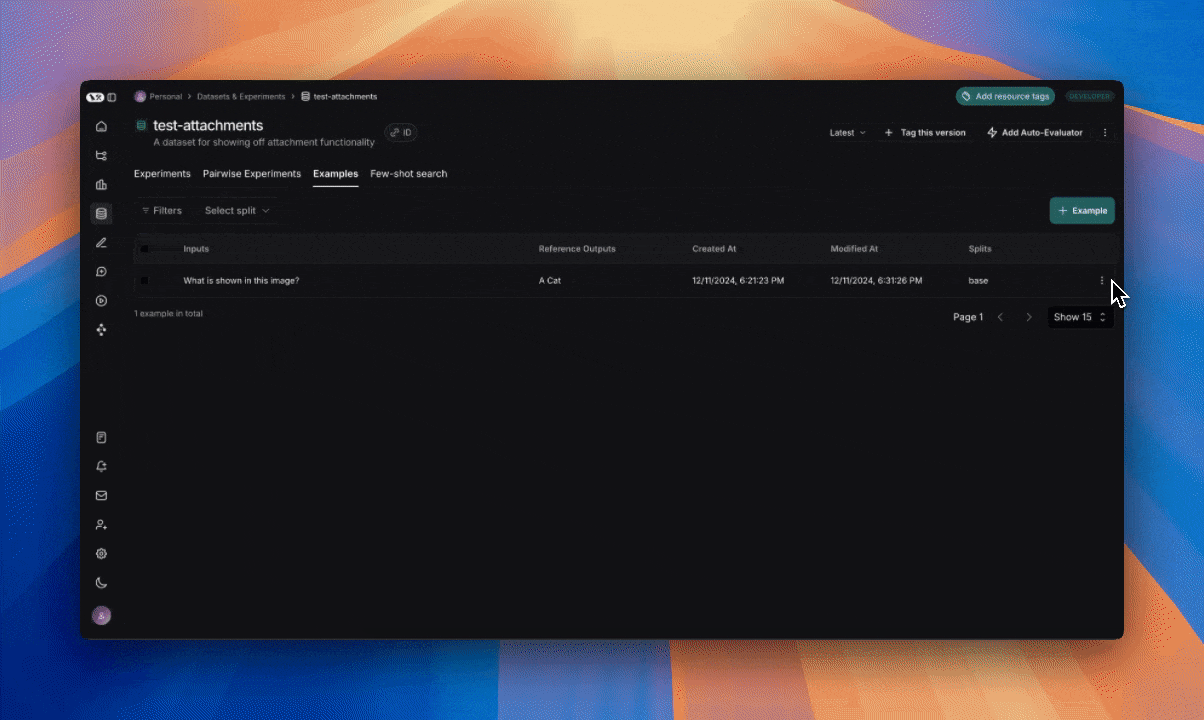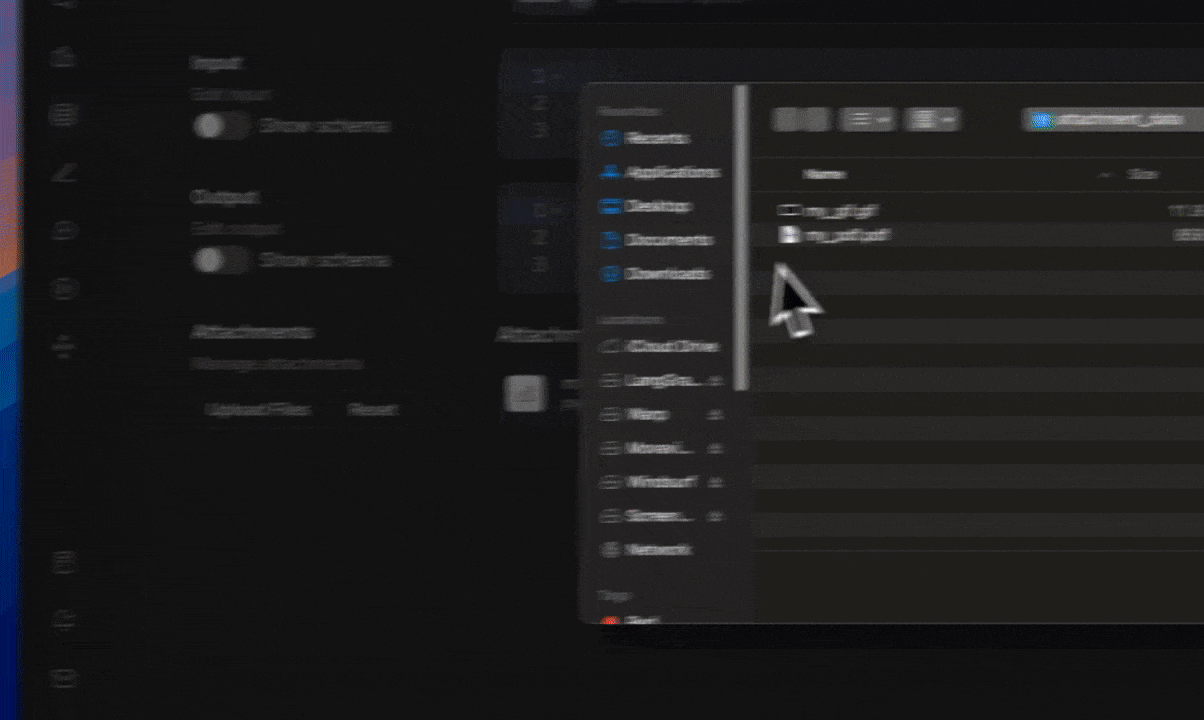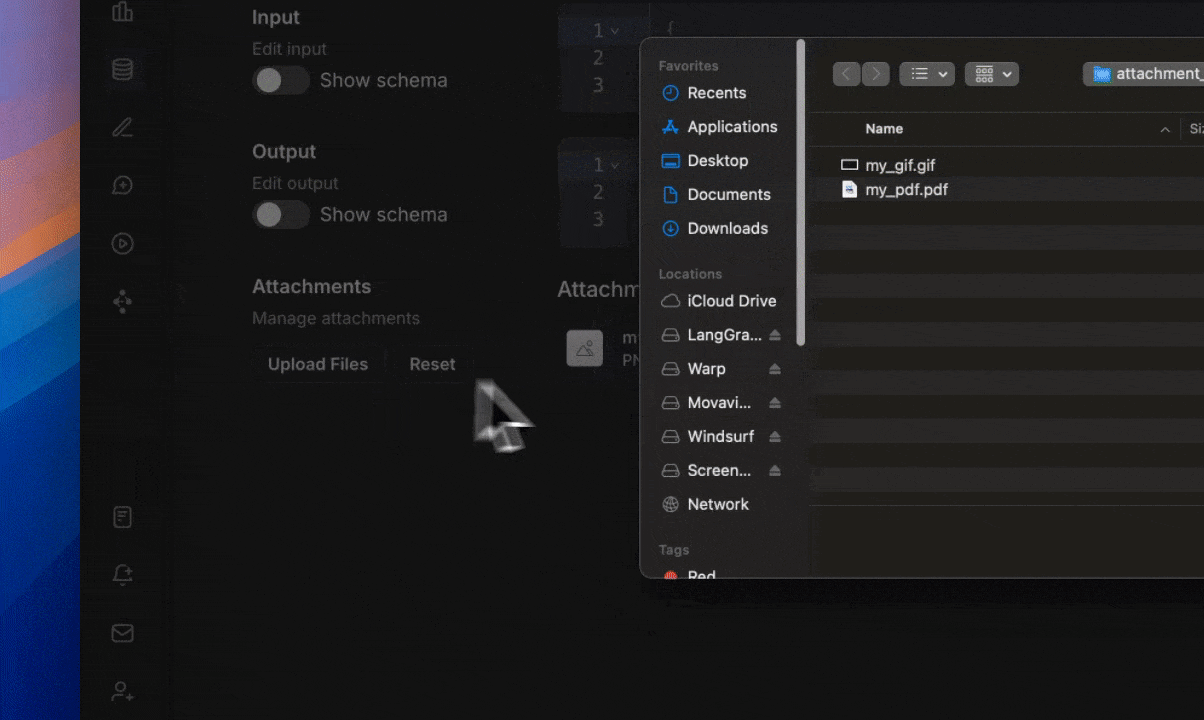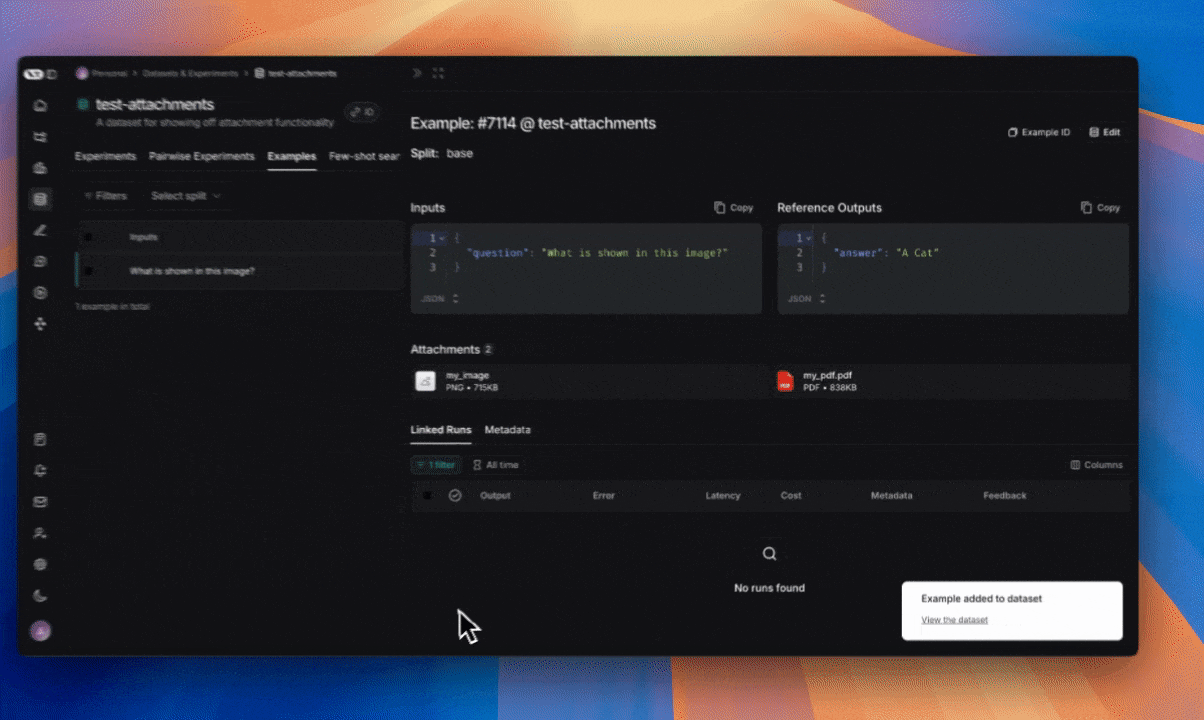
1. 创建带附件的示例
要使用 SDK 上传带附件的示例,请使用 create_examples / update_examples Python 方法或 uploadExamplesMultipart / updateExamplesMultipart TypeScript 方法。Python
需要langsmith>=0.3.13
TypeScript
需要版本 >= 0.2.13 您可以使用uploadExamplesMultipart 方法上传带附件的示例。 请注意,这与标准 createExamples 方法不同,后者目前不支持附件。每个附件都需要 Uint8Array 或 ArrayBuffer 作为数据类型。Uint8Array:用于直接处理二进制数据。ArrayBuffer:表示固定长度的二进制数据,可根据需要转换为Uint8Array。
除了以字节形式传入之外,附件还可以指定为本地文件路径。为此,请为附件
data 值传入路径并指定参数 dangerously_allow_filesystem=True2. 运行评估
定义目标函数
现在我们有了一个包含带附件示例的数据集,我们可以定义一个目标函数来对这些示例运行。以下示例仅使用 OpenAI 的 GPT-4o 模型回答有关图像和音频剪辑的问题。Python
您正在评估的目标函数必须有两个位置参数才能使用与示例关联的附件,第一个必须命名为inputs,第二个必须命名为 attachments。
inputs参数是一个字典,其中包含示例的输入数据,不包括附件。attachments参数是一个字典,它将附件名称映射到包含预签名 URL、mime_type 和文件字节内容读取器的字典。您可以使用预签名 URL 或读取器来获取文件内容。附件字典中的每个值都是一个具有以下结构的字典
TypeScript
在 TypeScript SDK 中,如果includeAttachments 设置为 true,则 config 参数用于将附件传递给目标函数。 config 将包含 attachments,它是一个对象,将附件名称映射到以下形式的对象:定义自定义评估器
以上相同的规则适用于确定评估器是否应接收附件。 下面的评估器使用 LLM 来判断推理和答案是否一致。要了解有关如何定义基于 LLM 的评估器的更多信息,请参阅本指南。更新带附件的示例
在上面的代码中,我们展示了如何向数据集添加带附件的示例。也可以使用 SDK 更新这些相同的示例。 与现有示例一样,当您使用附件更新数据集时,数据集会进行版本控制。因此,您可以导航到数据集版本历史记录以查看对每个示例所做的更改。要了解更多信息,请参阅本指南。 更新带附件的示例时,您可以通过几种不同的方式更新附件:- 传入新附件
- 重命名现有附件
- 删除现有附件
- 任何未明确重命名或保留的现有附件将被删除。
- 如果您向
retain或rename传入不存在的附件名称,将引发错误。 - 如果
attachments和attachment_operations字段中出现相同的附件名称,则新附件优先于现有附件。
UI
1. 创建带附件的示例
您可以通过几种不同的方式向数据集添加带附件的示例。来自现有运行
将运行添加到 LangSmith 数据集时,附件可以从源运行选择性地传播到目标示例。要了解更多信息,请参阅本指南。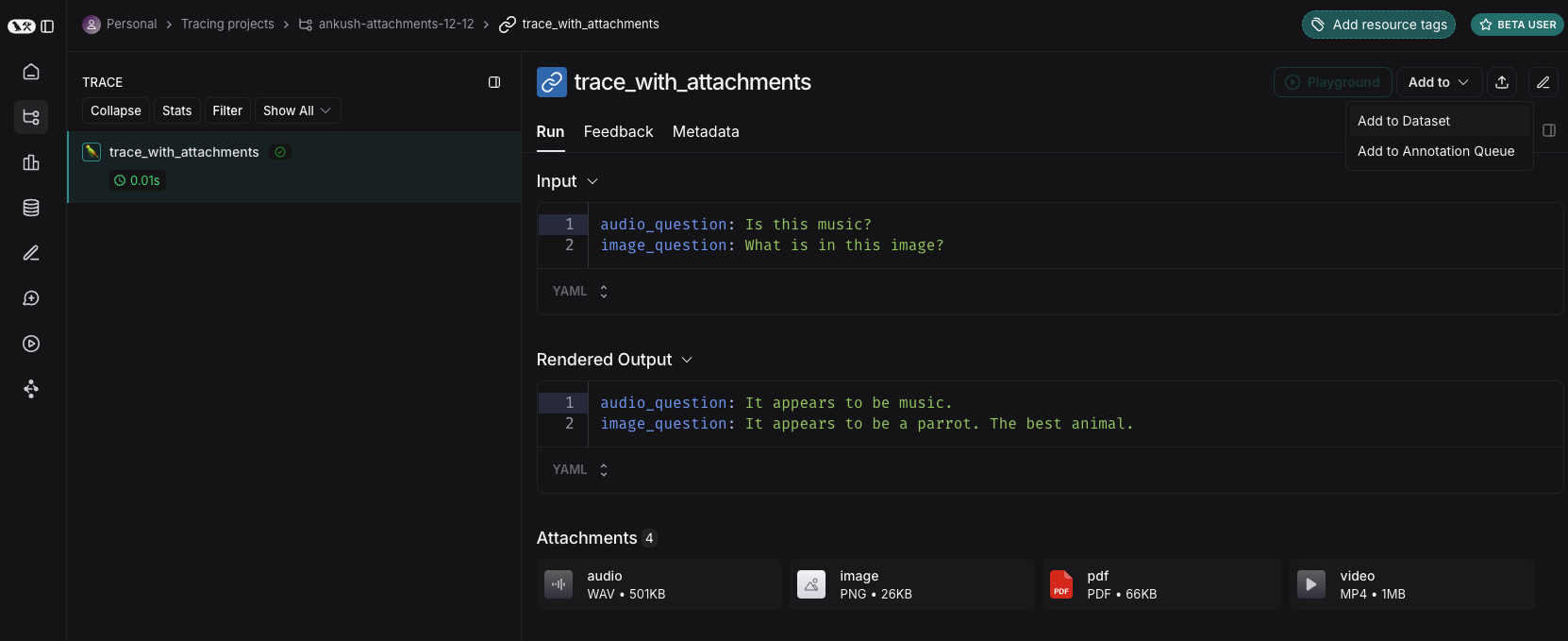
从头开始
您可以直接从 LangSmith UI 创建带附件的示例。单击数据集 UI 的“示例”选项卡中的+ Example 按钮。然后使用“上传文件”按钮上传附件: 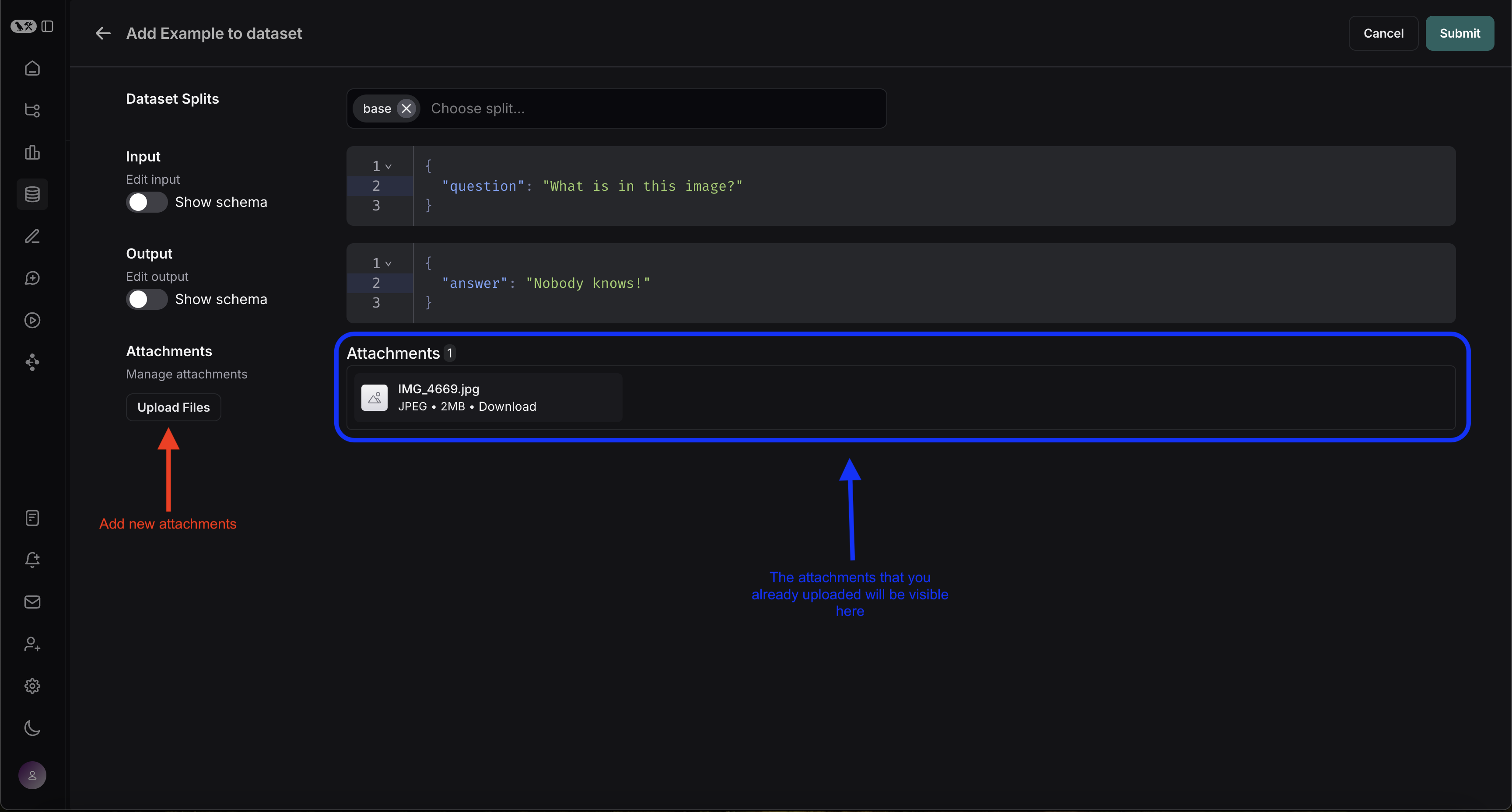
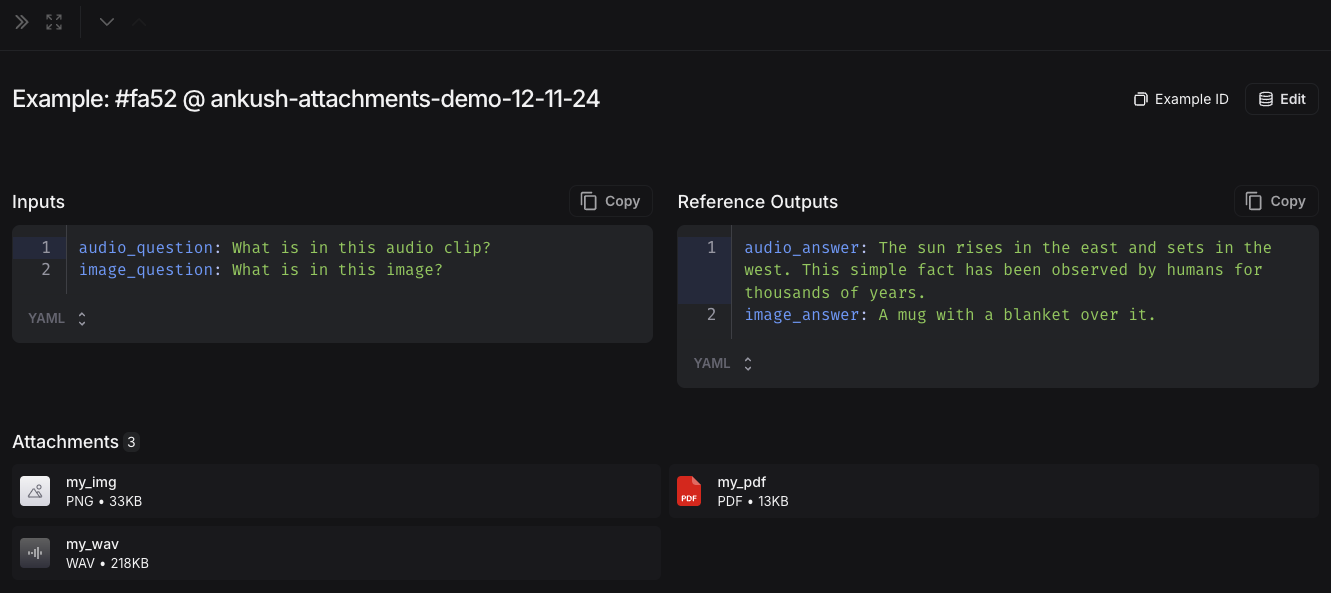
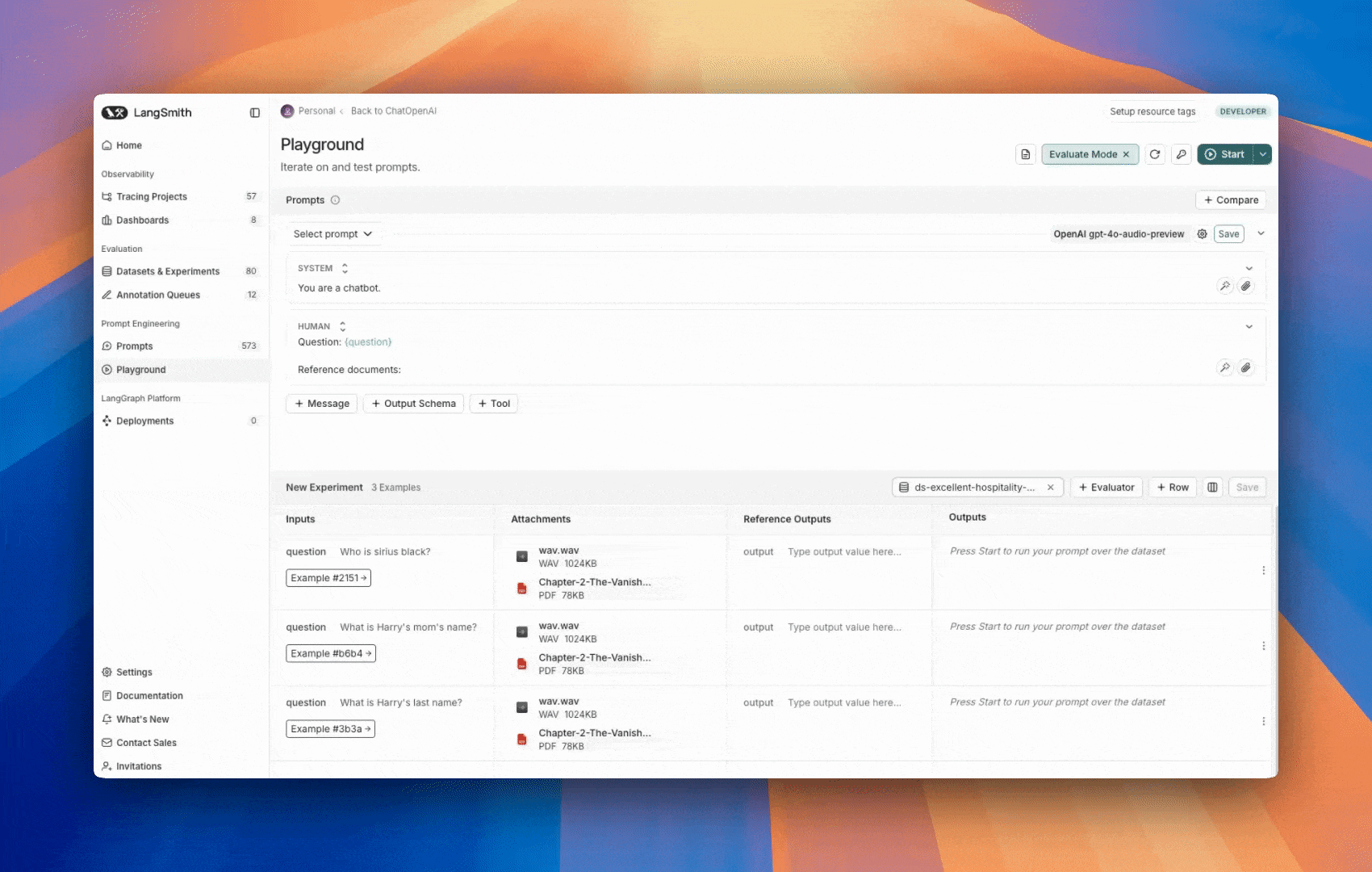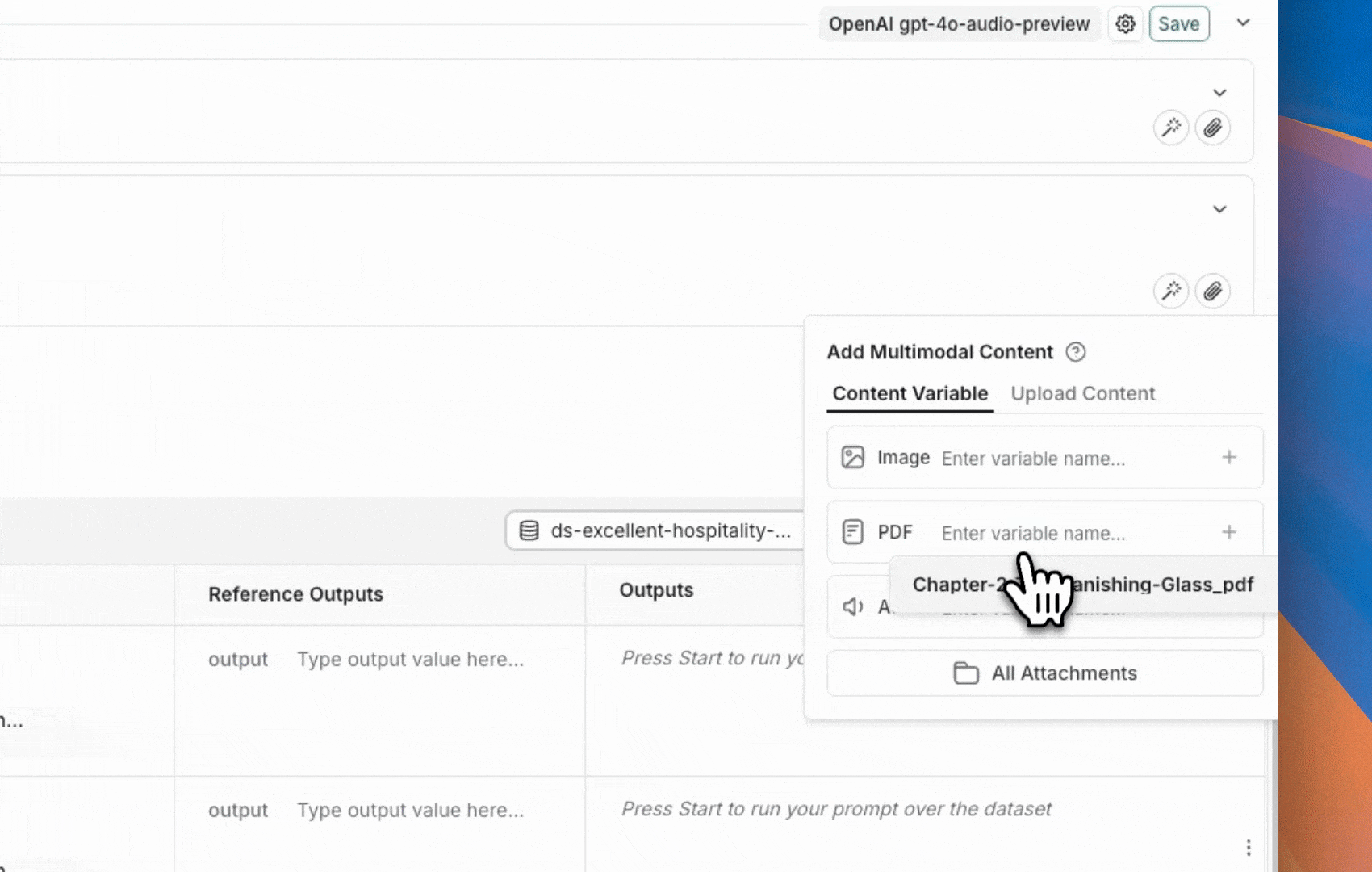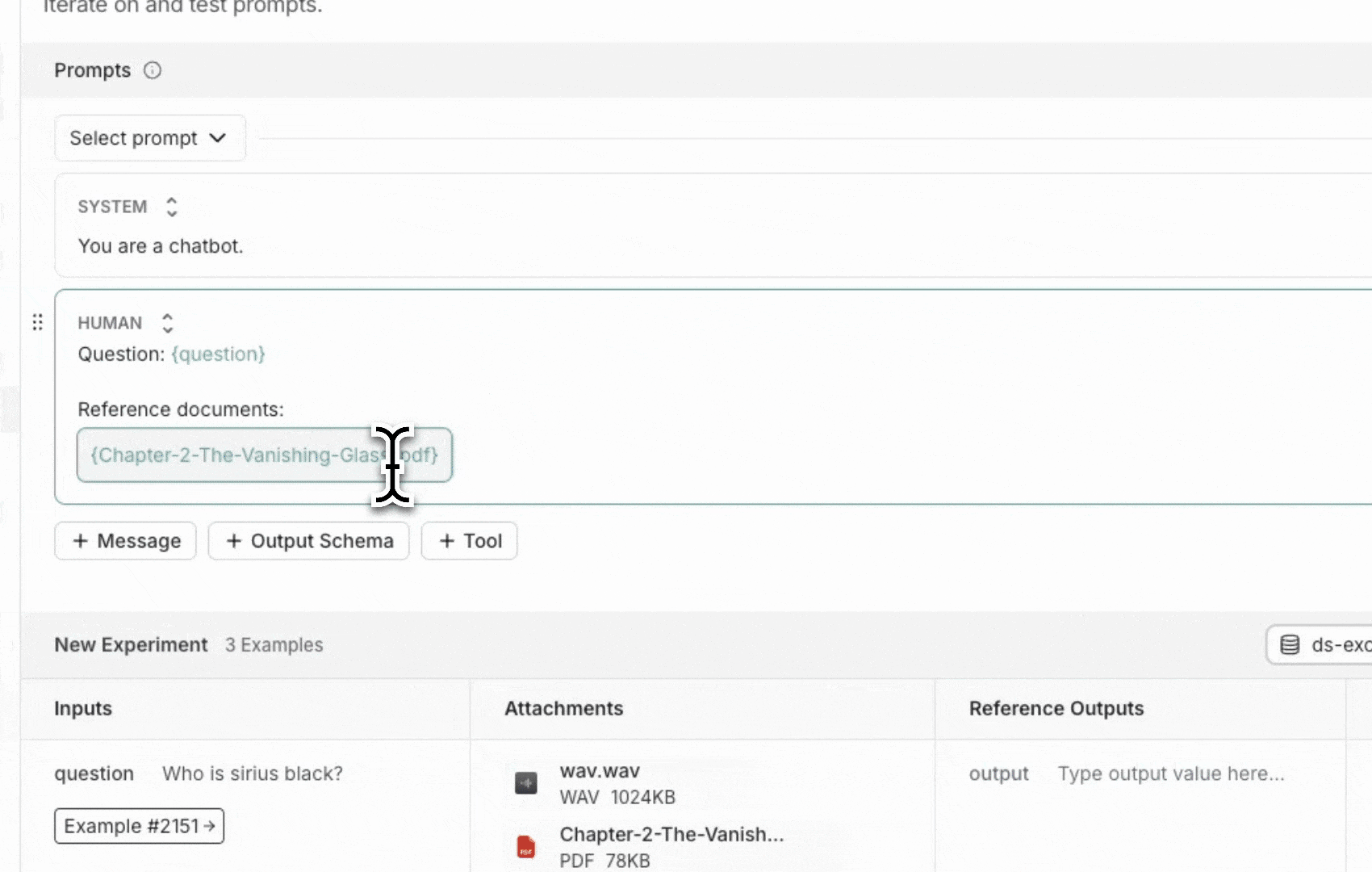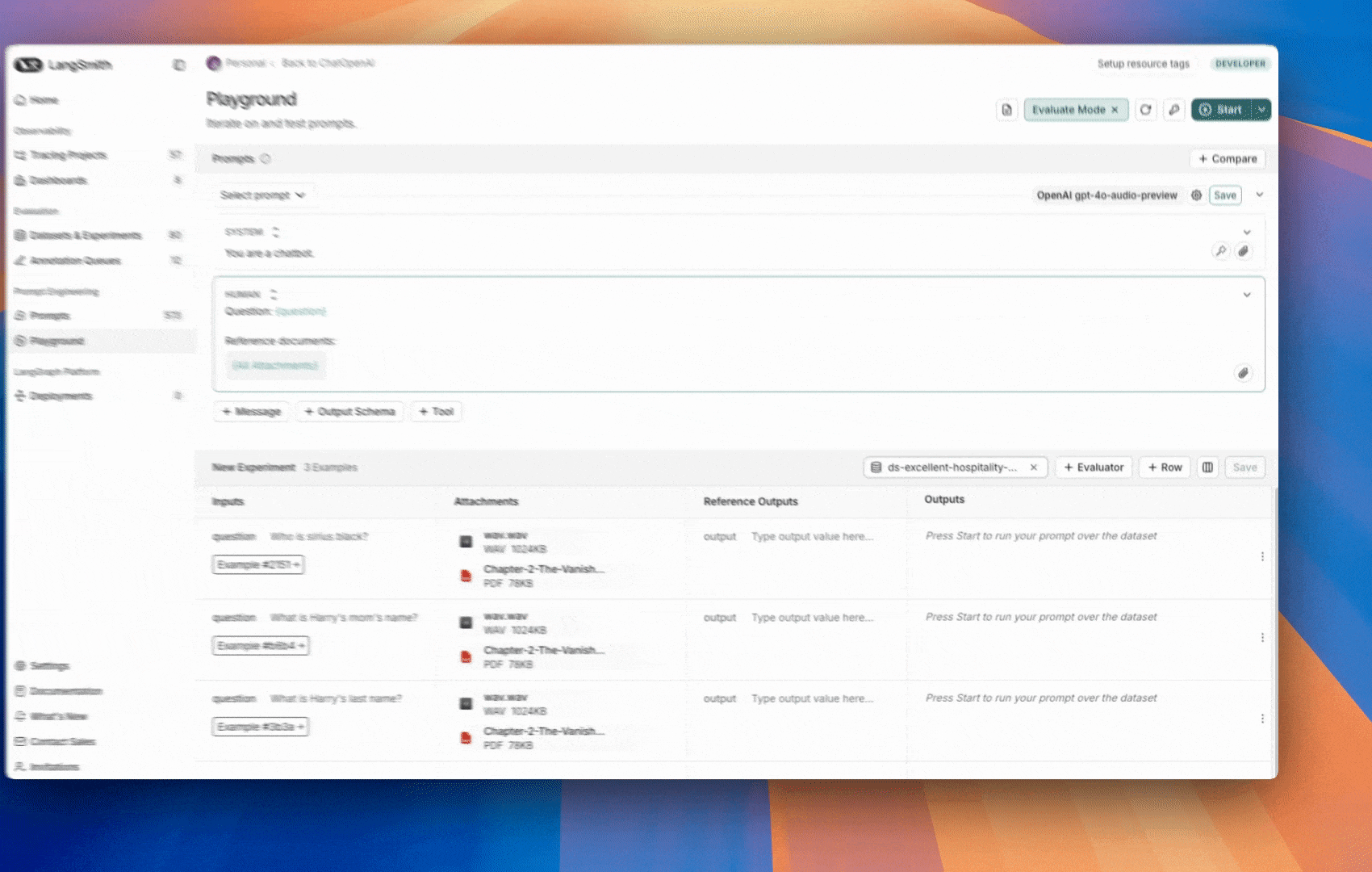
2. 创建多模态提示
LangSmith UI 允许您在评估多模态模型时在提示中包含附件: 首先,单击要添加多模态内容的消息中的文件图标。接下来,为您要为每个示例包含的附件添加模板变量。- 对于单一附件类型:使用建议的变量名。注意:所有示例都必须有一个同名附件。
- 对于多个附件,或如果您的附件名称在不同示例之间有所不同:使用
All attachments变量以包含每个示例的所有可用附件。
定义自定义评估器
LangSmith Playground 目前不支持将多模态内容拉取到评估器中。如果这对您的用例有帮助,请在 LangChain 论坛中告诉我们(如果您还不是会员,请在此处注册)!
- OCR → 文本校正:使用视觉模型从文档中提取文本,然后评估提取输出的准确性。
- 语音转文本 → 转录质量:使用语音模型将音频转录为文本,然后对照您的参考评估转录。
更新带附件的示例
UI 中的附件大小限制为 20MB。
- 上传新附件
- 重命名和删除附件
- 使用快速重置按钮将附件重置为以前的状态
以编程方式连接这些文档到 Claude、VSCode 等,通过 MCP 获取实时答案。